A training set for bike sharing forecasting
Last night I went to a Toulouse Data Science meetup. The talks were about generative AI and information retrieval, which aren’t topics I’m knowledgeable about. However, one of the speakers was a friend of mine, so I went to support him. Toulouse used to be my hometown, so I bumped into a few people I knew. It was a nice evening.
I chatted with an old office mate from when I interned at INSA Toulouse. He initially encouraged me to work on OpenBikes, which was a project to scrape bike sharing data in order to train a forecasting model. It never really made it into production. However, the project taught me a lot about machine learning and software engineering, and opened a few doors. I’m grateful for his advice at the time. I shut down the OpenBikes project when I started my PhD, due to a lack of time.
Last summer, I motivated myself to resurrect the scraping part of this project. I used Simon Willison’s git scraping technique. This enabled me to write a GitHub Action that manages to scrape data for >50 cities, in ~25 seconds, every 15 minutes.
Last night’s discussion has motivated me to put extra energy into this project. My friend is offering to put a model into production, if I provide him with a training set. Our (ambitious) plan is to build a model that could be helpful for the upcoming Olympic Games in Paris. I’m not sure if we’ll make it, but it’s a fun project to work on.
Anyway, enough about me and my life. I’m going to share some code to retrieve the data I’m scraping, and turn it into a training set for a forecasting model.
I’m storing the data in a Google Cloud Storage bucket. There’s one Parquet file for each city/provider/month. The data for a given month is archived once the month is over. A nifty way to access the data is via DuckDB, which provides a SQL interface to Parquet files. Here’s how to retrieve the data for Toulouse:
import duckdb
with duckdb.connect(":memory:") as con:
con.execute("SET s3_endpoint='storage.googleapis.com'")
updates = con.execute(f"""
SELECT *
FROM READ_PARQUET('s3://bike-sharing-history/toulouse/jcdecaux/*/*.parquet');
""").fetch_df() # this is a pandas DataFrame
print(
updates
.query("station == '00003 - POMME'")
.head()
.to_markdown(index=False)
)
| station | longitude | latitude | commit_at | skipped_updates | bikes | stands |
|---|---|---|---|---|---|---|
| 00003 - POMME | 1.44545 | 43.6033 | 2023-08-05 12:00:02 | 0 | 14 | 4 |
| 00003 - POMME | 1.44545 | 43.6033 | 2023-08-05 12:56:53 | 10 | 17 | 1 |
| 00003 - POMME | 1.44545 | 43.6033 | 2023-08-05 13:19:12 | 0 | 14 | 4 |
| 00003 - POMME | 1.44545 | 43.6033 | 2023-08-05 13:31:18 | 0 | 12 | 6 |
| 00003 - POMME | 1.44545 | 43.6033 | 2023-08-05 13:33:18 | 0 | 14 | 4 |
The GitHub Action scrapes the API of each bike sharing system every 15 minutes. There is no need to record the current state if nothing changed at a given bike station. The skipped_updates column indicates how many updates were skipped. This is a form of logical compression which saves a lot of disk space. The commit_at column indicates when the data was recorded. The bikes and stands columns indicate the number of bikes and stands at the station. The longitude and latitude columns indicate the geographical location of the station.
The above format can be turned into a full history by inferring each bike station’s state at given points in time. There is no deterministic to know the exact state of a bike station at a given point in time. Indeed, the number of bikes/stands might fluctuate between the different moments when the data is scrapped. However, we can make an educated guess by looking at the last known state of the station. Here’s an example:
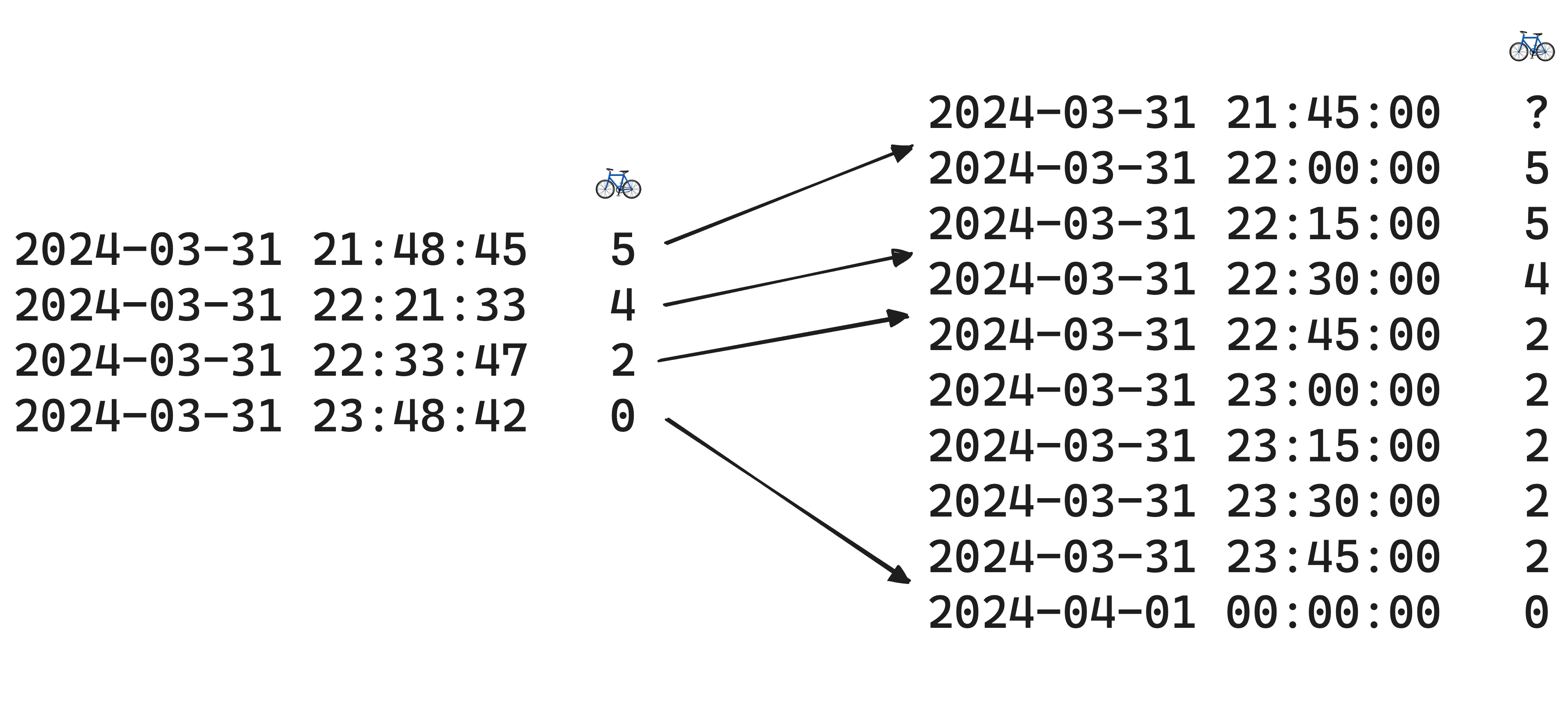
The idea to define a 15 minutes schedule, and to fill the gaps with the last known state of the station. Here’s how to do it with pandas’ resample method:
history = (
updates
.groupby('station')
.resample(
rule='15min',
on='commit_at'
).max()
.drop(columns='station')
.groupby('station').shift(1)
.groupby('station').ffill()
.dropna(subset=['skipped_updates'])
[['bikes', 'stands']].astype('uint8')
)
print(
history
.query("station == '00003 - POMME'")
.head()
.to_markdown()
)
| time | bikes | stands |
|---|---|---|
| 2023-08-05 12:15:00 | 14 | 4 |
| 2023-08-05 12:30:00 | 14 | 4 |
| 2023-08-05 12:45:00 | 14 | 4 |
| 2023-08-05 13:00:00 | 17 | 1 |
| 2023-08-05 13:15:00 | 17 | 1 |
I want to emphasize this is just one way of doing it. Indeed, the exact state of a station at any given time is not known to us, so it has to be inferred. The above solution is not perfect, but it’s a start, and it’s definitely sufficient for training a forecasting model. A simple solution would be to increase the frequency at which the data is scraped, but I don’t have the budget for that.
For this problem, a useful model would be able to predict the amount of bikes in a station over the next 120 minutes, at 15 minutes intervals. Here’s how to create these targets:
bikes_ahead = (
history
.groupby('station')['bikes'].shift([-i for i in range(1, 9)])
.dropna()
.astype('uint8')
)
bikes_ahead.columns = [f'bikes_+{15 * i}min' for i in range(1, 9)]
print(
bikes_ahead
.query("station == '00003 - POMME'")
.head()
.to_markdown()
)
| bikes_+15min | bikes_+30min | bikes_+45min | bikes_+60min | bikes_+75min | bikes_+90min | bikes_+105min | bikes_+120min | |
|---|---|---|---|---|---|---|---|---|
| 2023-08-05 12:15:00 | 14 | 14 | 17 | 17 | 14 | 14 | 18 | 18 |
| 2023-08-05 12:30:00 | 14 | 17 | 17 | 14 | 14 | 18 | 18 | 18 |
| 2023-08-05 12:45:00 | 17 | 17 | 14 | 14 | 18 | 18 | 18 | 16 |
| 2023-08-05 13:00:00 | 17 | 14 | 14 | 18 | 18 | 18 | 16 | 15 |
| 2023-08-05 13:15:00 | 14 | 14 | 18 | 18 | 18 | 16 | 15 | 18 |
The above DataFrame can be used to train a forecasting model. Here’s an example using a HistGradientBoostingRegressor from scikit-learn, which is their LightGBM-like implementation:
from sklearn import ensemble
from sklearn import model_selection
model = ensemble.HistGradientBoostingRegressor(
loss='poisson',
random_state=42
)
features = history.loc[bikes_ahead.index]
cv = model_selection.GroupKFold(n_splits=5)
groups = bikes_ahead.index.get_level_values('station')
for target_col in bikes_ahead.columns:
scores = model_selection.cross_val_score(
model,
features,
bikes_ahead[target_col],
groups=groups,
cv=cv,
scoring='neg_mean_squared_error'
)
print(f'{target_col} — {-scores.mean():.2f} ± {scores.std():.2f}')
bikes_+15min — 1.09 ± 0.05
bikes_+30min — 2.24 ± 0.11
bikes_+45min — 3.41 ± 0.17
bikes_+60min — 4.57 ± 0.23
bikes_+75min — 5.74 ± 0.29
bikes_+90min — 6.89 ± 0.34
bikes_+105min — 8.03 ± 0.39
bikes_+120min — 9.14 ± 0.43
These figures provide a baseline. The model is not very good, but there is room for improvement. We could add some time-based features. We could also leverage the geographical layout of the stations. Moreover, the regression task could be framed differently. For instance, we could predict the number of bikes that will be taken/added, instead of directly predicting the number of bikes. This could be an easier task for the model.
In addition to bike sharing data, I’ve collected weather data from Open-Meteo. Instead of just storing the current weather, I’ve stored short-term forecasts, relative to the moment when the data is scrapped. This data could be used to improve the model. For instance, the model could learn that people are less likely to take a bike if it’s likely to rain in 30 minutes. The weather data is stored similarly to the bike sharing data. Here’s how to retrieve it:
with duckdb.connect(":memory:") as con:
con.execute("SET s3_endpoint='storage.googleapis.com'")
weather = con.execute(f"""
SELECT *
FROM READ_PARQUET('s3://weather-forecast-history/toulouse/*/*.parquet');
""").fetch_df()
print(weather.head().to_markdown(index=False))
| commit_at | forecast_at | temperature | rain | wind_speed |
|---|---|---|---|---|
| 2023-08-01 01:44:46 | 2023-08-01T00:00 | 19.5 | 0 | 10.3 |
| 2023-08-01 01:44:46 | 2023-08-01T01:00 | 18.3 | 0 | 8.3 |
| 2023-08-01 01:44:46 | 2023-08-01T02:00 | 17.9 | 0 | 6.6 |
| 2023-08-01 01:44:46 | 2023-08-01T03:00 | 17.8 | 0 | 5.5 |
| 2023-08-01 01:44:46 | 2023-08-01T04:00 | 17.3 | 0 | 5.7 |
Using weather data can be tricky, though, because in production you’ll have to retrieve the weather forecast in order to make a prediction. It’s straightforward, but it’s an extra step that has to be justified.
That’s it, I hope this can be useful to some people. As for our objective of building a model for the Olympic Games, it turns out that the Paris API was updated last fall! There is a new endpoint, which I shall start scraping right away 🏃♂️