A rant against dbt ref
Table of contents
Disclaimer
Let me be absolutely clear: I think dbt is a great tool. Although this post is a rant, the goal is to be constructive and suggest an improvement.
dbt in a nutshell
dbt is a workflow orchestrator for SQL. In other words, it’s a fancy Make for data analytics. What makes dbt special is that it is the first workflow orchestrator that is dedicated to the SQL language. It said out loud what many data teams were thinking: you can get a lot done with SQL.
A workflow orchestrator is necessary to organise tasks into a DAG, and then execute (a subset of) tasks in the correct order. Some orchestrators need to be told which tasks depend on other tasks. Other might determine dependencies automatically. A good orchestrator should trivialise this operation and make you feel productive.
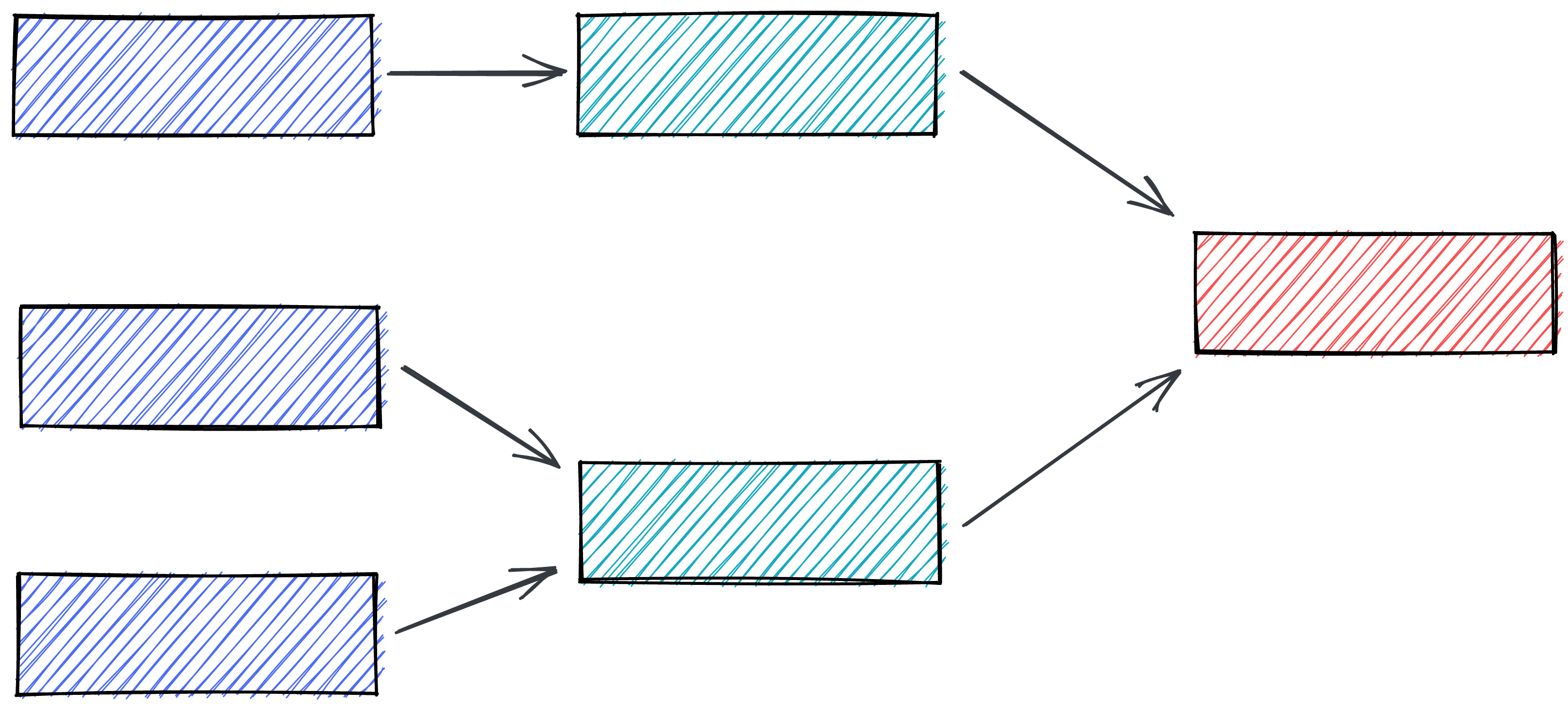
The good
The emergence of dbt is one of the nicest things that happened to the data analytics field in recent years.
There’s no doubt about dbt being an influential tool. Instead of improving an existing workflow, it created its own paradigm. To me, it feels like what scikit-learn did for machine learning with its fit/predict concept, or what columnar databases did when they ousted Hadoop. dbt is setting a standard which most of its users seem to agree on.
dbt encourages you to massage your data in SQL rather than in, say, Python. SQL is a language that was designed to manipulate data, which is likely why dbt feels so natural. The rumors that many teams are adopting it is a testimony to dbt’s pervasiveness.
Just this week I chuckled while reading blef.fr, when I learned about a new tool called fal. The latter presents itself as “dbt for Python”. To me that’s just a sexier way to say “Airflow”. The fact that dbt is generating offsprings tells you it caught the Zeitgeist. In short, dbt is à la mode.
The bad
And yet, from where I stand, all that glitters is not gold.
One of dbt’s central features is the ref function. In fact, to quote their documentation:
The most important function in dbt is ref(); it’s impossible to build even moderately complex models without it.
With dbt, instead of writing literal table names, you reference them:
-- before
SELECT user_id, COUNT(*)
FROM users
LEFT JOIN purchases
GROUP BY user_id
-- after
SELECT *
FROM {{ ref('users') }}
LEFT JOIN {{ ref('purchases') }}
GROUP BY user_id
What’s the point? Again, I’ll quote the documentation:
ref()is, under the hood, actually doing two important things. First, it is interpolating the schema into your model file to allow you to change your deployment schema via configuration. Second, it is using these references between models to automatically build the dependency graph. This will enable dbt to deploy models in the correct order when usingdbt run.
The crux of my rant is around their second point. I hate that you have to specify dependencies by hard-coding them with ref(something). It feels like the opposite of magic. I shouldn’t have to hold dbt’s hand and tell it what my query depends on. I would instead expect dbt to parse my SQL and determine the dependencies by itself. From my experience, you can already get a lot covered with a bit of regex:
import re
query = """
SELECT user_id, COUNT(*)
FROM users
LEFT JOIN purchases
GROUP BY user_id
"""
pattern = (
r'(FROM|(LEFT|RIGHT|INNER|OUTER)? JOIN) (?P<table>\w+)'
)
dependencies = {
match.group("table")
for match in re.finditer(pattern, query)
}
The thing I dislike about ref is that I can’t just copy/paste my SQL query into my database client and execute it. I have to fiddle about and remove the curly braces and single quotes by hand for it to run. It’s annoying to me because I like debugging queries that way. Granted, you can access the compiled SQL in the target directory which dbt generates. In fact, there’s a section in dbt’s FAQ about this. But this isn’t a design decision which pushes you into The Pit Of Success.
I do however agree with their first point. It’s important to be able to build your tables in different environments, such as development or staging, as well as in production. However, I would argue there are alternative ways to do this. At Alan we had our own dbt-like tool, and we just prepended a schema to our output tables. We didn’t need anything like this ref function.
The ugly
Rant aside, the real problem with the ref function is that you can still write your queries without it. The issue is that when dbt determines the dependencies, builds the execution DAG, and runs the queries in the resulting order, it won’t magically indicate you forgot to specify a ref. Therefore, if your query $Q$ depends on a table $X$, there’s no guarantee that said table $X$ will be refreshed when $Q$ is executed.
This can lead to silent bugs, akin to what Donald Rumsfeld would call unknown unknowns. Things get even worse if you start executing views in parallel. Indeed, the bug will become transient and you won’t be able to reproduce it in a reliable manner. The result is a recipe for headaches.
Sure, there are ways to avoid this issue. You could visually inspect the execution DAG. You could rely on your colleagues, if you have any, to review your code. You could also add a linter in your CI routine to check this for you. But all these options feel like duct tape to me. By design, a good workflow orchestrator should have guardrails which prevent this issue in the first place.
A humble suggestion
In my opinion, dbt should determine dependencies by parsing the raw SQL code. The ref function shouldn’t exist. I gave a piece of Python code above to do this with a regex pattern. But SQL is a formal language, so instead of messing about with regexes, you can use a dedicated parser such as sqlparse. There’s also an example of extracting table names from a query in sql-metadata.
Of course, I don’t understand all the ramifications the change I suggest would imply. And I’m sure there are some good reasons why the ref function was introduced. Still, I would much rather use a version of dbt that doesn’t have the ref function. Actually, I’m so adamant on this that I wrote my own dbt-like tool at my day job. It’s 240 lines of Python, including empty lines and comments. It doesn’t have the all the templating bells and whistles dbt has, but it does the job and makes me feel productive. In particular, it works with views written in SQL as well as Python. Here is the code for posterity:
minidbt.py
"""
Usage example:
python minidbt.py
python minidbt.py --only view_A --only view_B
python minidbt.py --start view_A
python minidbt.py --end view_B
python minidbt.py --viz
This works for SQL (.sql) as well as Python (.py) views.
The views are assumed to be stored in a views directory.
"""
import abc
import ast
import dataclasses
import importlib
import itertools
import os
import pathlib
import re
import typing
import networkx as nx
import typer
from google.cloud import bigquery
@dataclasses.dataclass
class View(abc.ABC):
path: pathlib.Path
def __post_init__(self):
if not isinstance(self.path, pathlib.Path):
self.path = pathlib.Path(self.path)
@property
def name(self):
return self.path.stem
@classmethod
def from_path(cls, path):
if path.suffix == ".py":
return PythonView(path)
if path.suffix == ".sql":
return SQLView(path)
@property
@abc.abstractmethod
def dependencies(self) -> typing.Set[str]:
...
@abc.abstractmethod
def run(self, client):
...
class SQLView(View):
@property
def query(self):
return self.path.read_text().rstrip().rstrip(";")
@property
def cte_names(self):
pattern = r'"?(?P<table>\w+)"? AS \('
return {
match.group("table")
for match in re.finditer(pattern, self.query, re.IGNORECASE)
}
@classmethod
def _parse_sql_dependencies(cls, query):
pattern = (
r'(FROM|(LEFT|RIGHT|INNER|OUTER)? JOIN) "?(?P<schema>\w+)\.(?P<table>\w+)"?'
)
return {
match.group("table") for match in re.finditer(pattern, query, re.IGNORECASE)
}
@property
def dependencies(self):
return self._parse_sql_dependencies(self.query)
def run(self):
client = bigquery.Client()
job = client.create_job(
{
"query": {
"query": self.query,
"destinationTable": {
"projectId": "carbonfact",
"datasetId": "analytics",
"tableId": self.name,
},
"createDisposition": "CREATE_IF_NEEDED",
"writeDisposition": "WRITE_TRUNCATE",
}
}
)
job.result()
class PythonView(View):
@property
def dependencies(self):
def _dependencies():
code = self.path.read_text()
for node in ast.walk(ast.parse(code)):
# pd.read_gbq
try:
if (
isinstance(node, ast.Call)
and node.func.value.id == "pd"
and node.func.attr == "read_gbq"
):
yield from SQLView._parse_sql_dependencies(node.args[0].value)
except AttributeError:
pass
# .query
try:
if isinstance(node, ast.Call) and node.func.attr == "query":
yield from SQLView._parse_sql_dependencies(node.args[0].value)
except AttributeError:
pass
return set(_dependencies())
def run(self):
client = bigquery.Client()
mod = importlib.import_module("views")
output = getattr(mod, self.name).output
job_config = bigquery.LoadJobConfig(
schema=[],
write_disposition="WRITE_TRUNCATE",
)
job = client.load_table_from_dataframe(
output, f"carbonfact.analytics.{self.name}", job_config=job_config
)
job.result()
class DAGOfViews(nx.DiGraph):
def __init__(self, views: typing.List[View] = None):
super().__init__(
(dependency, view.name)
for view in views or []
for dependency in view.dependencies
)
# Some views have no dependencies but still have to be included
for view in views or []:
self.add_node(view.name)
def main(
only: typing.Optional[typing.List[str]] = typer.Option(None),
start: typing.Optional[str] = typer.Option(None),
end: typing.Optional[str] = typer.Option(None),
inclusive: bool = True,
viz: bool = False,
):
# Enumerate the views
here = pathlib.Path(__file__)
views = [
View.from_path(path)
for path in itertools.chain(
here.parent.glob("views/*.py"), here.parent.glob("views/*.sql")
)
if path.name != "__init__.py"
]
dag = DAGOfViews(views)
views = {view.name: view for view in views if view}
# Determine the execution order
if only:
order = only
elif start:
order = [start] if inclusive else []
for src, dst in nx.bfs_edges(dag, start):
if dst not in order:
order.append(dst)
elif end:
subset = {end} if inclusive else []
for src, dst in nx.bfs_edges(dag, end, reverse=True):
if dst not in subset and dst in views:
subset.add(dst)
order = list(nx.topological_sort(dag.subgraph(subset)))
else:
order = list(nx.topological_sort(dag))
# Visualize dependencies
if viz:
import graphviz
dot = graphviz.Digraph()
for node in dag.nodes:
style = {}
# Source tables
if node not in views.keys():
style["shape"] = "box"
# Views
else:
if isinstance(views[node], PythonView):
style["color"] = "darkgoldenrod2"
style["fontcolor"] = "dodgerblue4"
if node in order:
style["style"] = "filled"
style["fillcolor"] = "lightgreen"
dot.node(node, **style)
# Dependencies
for dst in dag.nodes:
for src in dag.predecessors(dst):
dot.edge(src, dst)
dot.render(view=True, cleanup=True)
return
# Run views
for view_name in order:
if not (view := views.get(view_name)):
continue
print(view.name, end="\r")
view.run()
print("\033[92m" + view.name + "\033[0m")
if __name__ == "__main__":
typer.run(main)
Thank you Clément Chastagnol for proofreading and suggesting edits.