Dynamic on-screen TV keyboards
Table of contents
This article has some interactive keyboards, therefore I recommend reading it from your computer rather than your phone.
On-screen TV keyboards
I’ve recently been spending time at my brother’s place. We usually eat in front of TV. I’ve thus found myself typing stuff on the Netflix/Amazon/Plex TV apps. The typing happens through a remote controller, which is slower than typing with ones fingers. However, the TV apps usually suggest the correct show/movie after five or six keystrokes, so it’s not that bad.
Typing stuff via an on-screen TV keyboard with a remote controller isn’t something one does very often. It’s likely pointless to try optimizing this process. And yet, I felt compelled to explore more efficient keyboard layouts.
In particular, I immediately wondered why these keyboards didn’t reorganise their layout dynamically based on the current input. I did some research, and stumbled on this article comparing different TV keyboards back in 2017. The article mentions a Samsung TV that suggests the four most likely next characters:
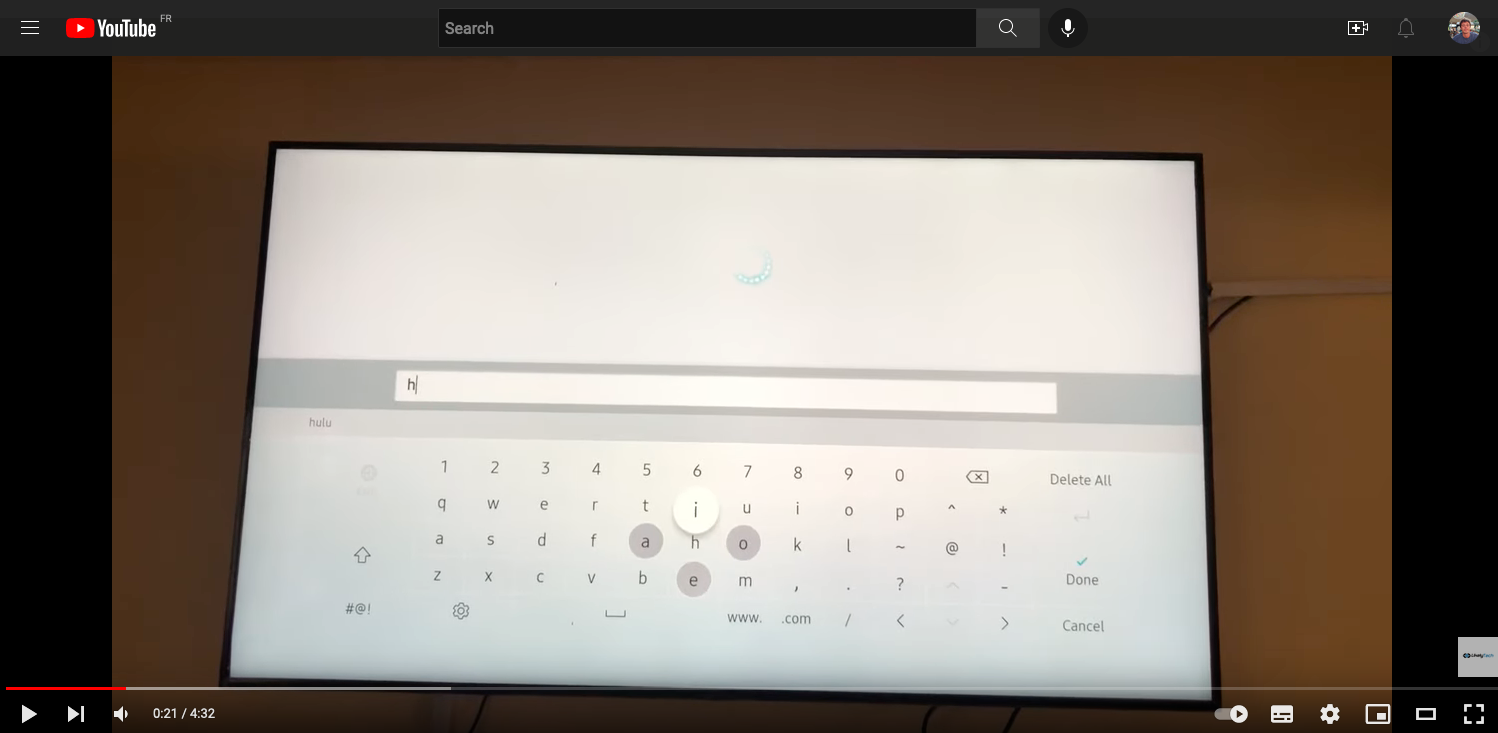
I decided to work on a more general prototype, and to implement my own algorithm. I had some experience measuring keyboard efficiency, so I was confident it would be straightforward to measure the performance gain of a dynamic keyboard. But first, I wrote a little something in Vue.js to simulate a TV keyboard:
✍️ — '[[ input ]]'
📐 — [[ distances.reduce((sum, x) => sum + x, 0) ]]
This keyboard lacks realism in that you can point-and-click on it, as opposed to navigating with directional arrows. I’m also only considering the Latin alphabet and numbers. I’d also like to mention I’m going to ignore torus keyboards which wrap-around the edges, because they don’t seem common. Anyway, this keyboard has the merit of being interactive, and it can be used to measure the travel distance of an input.
What I call travel distance is the amount of necessary ⬆️⬇️⬅️➡️ movements to input a sentence. Note that the first position is always the top-left corner. My goal in this article is to design a dynamic keyboard which minimizes this distance. I’ll be benchmarking it against a static keyboard with a list of Netflix titles, which I found here.
Note: the source code for each keyboard is embedded into this page’s source code.
A dynamic layout algorithm
Distance between keys
The basic idea is that when you press a key, you want the keyboard to be layed out in such a manner that the next likely characters are close by. A static keyboard organised in alphabetical order is not optimal in that sense. It doesn’t take into account the frequency of juxtaposed characters. Other static keyboards take this into account, such as the QWERTY and AZERTY layouts. However, the latter were designed for physical keyboards, where the layout can’t change dynamically. We can do whatever we want with a virtual keyboard.
For an on-screen TV keyboard, it makes sense to measure the distance between keys with a taxicab geometry. Indeed, one can only go ⬆️⬇️⬅️➡️ with a remote controller. The following grid is interactive, and indicates a key’s distance with respect to the last key that was pressed:
Now let’s assume we have some method to determine the most likely next keys following one keypress. We can use more or less sophisticated probability models to do this. I’ll get back to that afterwards. Anyway, assuming we can order keys by some measure of likelihood, in what order should we lay them out on the keyboard?
Ordering keys around the previous keypress
We know the distance of each key with respect to the last keypress, so we can use said distance to determine the order. The only thing to clarify is the handling of keys that have the same distance. I cooked up a heuristic: keys closest to the keyboard’s center should be used in priority. The reasoning is that you want keypresses to occur away from the edges and corners, because those spots have less keys available around them.
The following interactive grid shows what this ordering algorithm looks like. The adjacent keys to the last keypress are prioritized. The distance to the center is used as a tiebreaker. Note that for a keyboard with an uneven number of columns and/or rows, the column and/or row numbers should be used as extra tiebreakers.
A basic probability model
We now have an algorithm to lay out a keyboard, with respect to the last key that was pressed. We know what character a keypress would correspond to, so all we need is a lookup table indicating which keys are the most likely to be pressed next. A simple solution is to build a probability model that measures the likelihood of a character appearing after another one:
$$P(c_i \mid c_{i-1}) = \frac{\sum_{w \in W}\sum_{j = 1}^{|w|} \mathbb{1}(w_{j-1} = c_{i-1}, w_j = c_i)}{\sum_{w \in W}\sum_{j = 1}^{|w|} \mathbb{1}(w_{j-1} = c_{i-1})}$$
This is just a fancy way of saying that we have to count how many times a character $c_i$ appears after another character $c_{i-1}$. Then we divide that by the total number of occurrences for $c_{i-1}$. That gives us a probability distribution over characters.
The set $W$ contains sentences over which to count. I’ve used this list of Netflix titles to do that. Here is a Python script to parse said list of titles, do the counting, and create a priority list for each keypress:
Click to see the code
import collections
import json
import requests
import string
titles = (
requests
.get('https://raw.githubusercontent.com/andrewhood125/netflix-search-cli/master/movieList.txt')
.content
.decode()
.splitlines()
)
titles = (movie.split('|')[0].split('(')[0] for movie in movies)
titles = (title.translate(str.maketrans('', '', string.punctuation)) for title in titles)
titles = (title.strip() for title in titles)
titles = (title.lower() for title in titles)
titles = (title.replace('�', '') for title in titles)
titles = list(titles)
counts = collections.Counter(
(prev_char, char)
for title in titles
for prev_char, char in zip(title, title[1:])
)
chars = set(''.join(titles))
P = {
prev_char: {
char: p_char
for char in chars
if (p_char := (
sum(c for (a, b), c in counts.items() if a == prev_char and b == char) /
sum(c for (a, b), c in counts.items() if a == prev_char)
))
}
for prev_char in chars
}
most_common_after = {
prev_char: ''.join(sorted(P[prev_char], key=P[prev_char].get, reverse=True))
for prev_char in chars
}
print(json.dumps(
most_common_after,
indent=4,
sort_keys=True
))
{
" ": "tsoabmcfwdligphrenk jvuy231qz75x49680",
"0": " 01s345t7298",
"1": "9310 26857s4",
"2": " 01954287hnmok6g",
"3": "0 15td294rb763",
"4": " 0t329146758",
"5": " 0t81475i",
"6": " 6t07el53",
"7": " 06t1435",
"8": " 0248137hmt6",
"9": " 18790245ta63",
"a": "nrlts mdciypgkvubfwhazxejoq",
"b": "eaoluri ybcsjtmhdfqn1zkw3",
"c": "haoekrt iluyncswbdqgmv",
"d": " eaiosryduvltgnhwmbfzcjpkx",
"e": " rsnadltecyvmxogpwfibkuhzqj21",
"f": " roiaefultysgnkpbmcdx",
"g": " ehrioauslgnytdmfbvkjcw",
"h": "eoia turynsmlbwdfchqjvp2g",
"i": "ncteslogrdvma fpbkizxuqjwhy58",
"j": "oaeui rhfcdynm",
"k": "ie sanyoulhrtmbfd91kp2jvwg",
"l": "eial odsyutkbmfvpcrhwgnzj1",
"m": "aeoi ypubsmrncwlthdfxj1kg",
"n": " gdetaisconkybufvhljrmzqwxp",
"o": "nrfum lowsdvtcpgbykaiehxjzq",
"p": "earoihl psutydfbmnkc5w",
"q": "u saowi",
"r": "ei aosytldnurkcmgvpbfhwzjqx",
"s": " teishaoupclkwmynqbfdrgv2z",
"t": "h eioarsutylcmwznbdgpfk2jv",
"u": "rnstlmeipgcb adfxykovjzuh2q5",
"v": "eiaos yrupnjkd",
"w": "aieoh nswrblydukcmtpfjzg",
"x": " ptiaexyomfucswrbh2",
"y": " soealnmptibwrcdzfgkuhvjyq",
"z": "aoe izyluhmtkw"
}
We also need to list the most common characters for the first keypress. This is rather straightforward.
Click to see the code
print(''.join(
c[0]
for c in collections.Counter(''.join(title[0] for title in titles))
.most_common()
if c[0] != '_'
))
tsbacmdhfprlwngiekjovu31yqz2x456897
Piecing it together
Now we know how to order keys following a keypress. We also have a basic model to determine what keys are likely to be pressed next. We can implement a dynamic keyboard by putting these two building blocks together.
✍️ — '[[ input ]]'
📐 — [[ distances.reduce((sum, x) => sum + x, 0) ]]
The keys are first layed out according to the likelihood of a character appearing in the first input position. Next, when a key is pressed, the matching position and character are stored. This triggers a refresh of the keyboard, whereby each key is assigned with an integer indicating its number in the order. Then, the lookup table for the last key that was pressed is used to assign a character to each key. It’s pretty straightforward, it just requires a bit of bookkeeping.
I suggest trying out the keyboard for yourself. For example, you can see that it reduces the distance for the three predefined titles by a non-negligible amount:
- The Last Dance goes from 64 to 14 (x4.6)
- House of Cards goes from 73 to 17 (x4.3)
- Peaky Blinders goes from 57 to 18 (x3.2)
Refining the probability model
One of the first things I noticed with this dynamic keyboard is that if I press e, the next suggested character is an empty space. I checked, and this is statistically correct. But it doesn’t make sense to suggest an empty space as the second character of a movie title – or any English sentence for that matter.
To alleviate this corner case, I tried out using a more granular probability model. I baked in the position of the next character. This essentially boils down to performing more counting and storing more values.
$$P(c_i \mid c_{i-1}) = \frac{\sum_{w \in W}\sum_{j = 1}^{|w|} \mathbb{1}(i = j, w_{j-1} = c_{i-1}, w_j = c_i)}{\sum_{w \in W}\sum_{j = 1}^{|w|} \mathbb{1}(i = j, w_{j-1} = c_{i-1})}$$
✍️ — '[[ input ]]'
📐 — [[ distances.reduce((sum, x) => sum + x, 0) ]]
You’ll notice that this keyboard suggests less characters than the previous one. That’s because characters which don’t appear after the previous one are discarded. And because we’re also encoding the character’s position, more cases are discarded. This somewhat reminds me inputting addresses in a GPS, where only plausible next characters are available when you type.
Benchmarking
A little while ago I wrote a small Python library called clavier. I used it to measure edit distances between OCR inputs and a database of correct inputs. Using the context keyboard’s physical helped making better spelling corrections.
Anyway, I did a few little changes to accomodate for a dynamic keyboard. This allowed to benchmark the three keyboards in this blog post. For each keyboard, I simply measured the amount of necessary ⬆️⬇️⬅️➡️ movements. I then plotted the distribution for each method and calculated some summary statistics. The code for running this benchmark is available here.

method mean std min 25% 50% 75% max
regular 75 48 2 42 64 97 393
dynamic 25 14 2 16 22 31 127
memorized 23 12 2 15 21 29 85
The dynamic keyboard is faster than the regular keyboard in 99% of cases. The more sophisticated dynamic keyboard – which is named memorized above – is faster than the dynamic one in 70% of cases. I actually expected the more granular probability model to be consistently better, but it wasn’t. And yet, my gut feeling is that there is still room for improvement. After all, the goal here is not to build a probability model that generalizes, but one that memorizes the list of titles.
However, one thing to take into account is the probability model’s memory usage. The first version I implemented is simple, and yet is elegant in that it only requires building a list of next characters for every character. The second model requires one entry for each character and each position. Any more sophisticated model would take up more space, which may be burdensome.
I was pleasantly surprised when I found out I wasn’t the first person to conduct a comparison between on-screen TV keyboards out in the open. Indeed, I found this technical blog post by Rick Wicklin comparing a Netflix keyboard to an Amazon keyboard on a list of popular movies from IMDB. I tried running my benchmark with his list of movies, but I wasn’t able to reconcile the figures he found for the Netflix keyboard. Rick’s experiment in SAS, and my university years are too far behind for me to dig into his implementation.
Conclusion
Is this really any faster? It is if you assume the distance between keystrokes is a good proxy for typing speed. However, I think that assumption is a bit weak in practice. I showed this dynamic keyboard to some friends. All of them mentioned being confused, and didn’t seem to be faster than with the regular keyboard. I did some tests myself, and I have to admit I didn’t notice a significant difference. However, you could argue that this simply takes some getting used to. But then again, it’s difficult to get used to something you don’t often use.
All in all I’m still convinced dynamic keyboards are worthwhile. Maybe they provide even more value for languages with longer alphabets than the Latin one. Personally, I’d love to see such a dynamic keyboard implemented in popular TV apps. Imagine the amount of seconds the human race would save in total – I’m just being sarcastic of course 😅.