The future of River
Table of contents
When I see tweets like this one, I’m both happy because people are aware of River, but also irked because it’s really difficult to make production-grade open source software.
We just had a developer meeting a week ago. We planned what we will work on during the first half of 2023. I thought it would be worthwhile to give a high-level view of how we envision River’s future. If not to be comprehensive, at least to reassure potential users that River is alive and kicking 🤺
I’d also like to emphasize that although we have a lot of plans for River, we’re still at the beginning of our journey. Good software takes time to build. Especially machine-learning software, if my experience is anything to go by!
Business as usual (mostly)
I started working on River during my PhD. At the time, my goal was to implement online machine learning algorithms that only existed in papers and blog posts. I wanted to provide a coherent interface, similar to what scikit-learn did for batch machine learning. This was a good excuse to hone both my machine learning and Python skills.
My belief is that River, Vowpal Wabbit, and scikit-learn’s partial_fit methods are at the front of the pack. Anyone wanting to do online machine learning is better off nowadays than they were a few years ago. I’m proud of what we’ve built, and more importantly the nice little community we’ve gathered. Definitely a lot of positive vibes 💫
And yet, I have to admit, sometimes I question whether what we’re doing with River is useful. Although I’m quite involved in machine learning, my personal belief is that it doesn’t necessarily have a significant positive impact on society. I’d like to be convinced otherwise, but until now I haven’t.
This doesn’t mean I work on River half-heartedly: I enjoy the technical challenge. It also makes me feel good when people use it. I’ve solved this conundrum in my life by working four days a week for a company cutting carbon emissions, while spending the rest of my time working on side-projects like River. It’s a healthy balance 🧘🏼♂️
Putting aside this “is ML useful?” question, I also sometimes have doubts as to whether River is useful as a machine learning toolbox. In the roughly four years River has existed, I’ve seen dozens of companies use it, and even more individuals/students. But it’s mostly been proof-of-concepts. Apart from a few exceptions, I haven’t heard of a company using River at a significant scale. Quoting a recent blog post from Fennel:
For most companies, the costs of maintaining this type of system outweigh the benefits it provides; if you even need to question whether you need online model training, you probably don’t.
I’m a pragmatic person. When I have to build a model at my day-job, I usually pick scikit-learn because batch learning is no-fuss. That’s the thing about online ML: it only makes sense for a subset of problems. Therefore, as an online ML library developer, it’s easy to wonder whether what I’m doing is a good use of my time.
I was pretty moved recently after watching Jiro Dreams of Sushi. It’s a story about a guy who spends all his life making sushi. He’s a shokunin: he hones his craft and seeks perfection, without worrying about what others are doing. He’s passionate, has a strong ethos, and believes in what he’s doing. The result is that he makes people happy and good things happen to him. He doesn’t feed thousands of people a day, but he does his part. I can’t compare myself to Jiro, but I like to think what online ML is to batch ML is what refined sushi is to fast food. And this is coming from a person who enjoys both.
Anyway, all this to say I’m well aware online ML is not as high-impact as regular ML. But who knows what the future is made of? Streaming analytics is definitely picking up, so there’s a good chance online ML will too. In the meantime, we’ll keep working on River and writing good code that people enjoy using. I also want to do everything I can to help people get acquainted with online ML. Contrary to batch ML, there’s a lack of tools and resources to get started.
TLDR: business as usual. We’re simply going to explore ways to make online machine learning practical and user-friendly, in addition to the ongoing development of River.
Beyond supervised learning
A lot of River’s development has focused around regression and classification. However, a lot of usecases don’t fit into either of these two paradigms. We’ve noticed that many people want to do anomaly detection, clustering, drift detection, recsys, forecasting, etc. Although we provide support for these usecases, many parts of River’s API are not as smooth as they could be. For instance, right now River doesn’t provide an easy way to evaluate an anomaly detection model. We will improve our support for these learning paradigms during the upcoming year, and beyond.
A focus on performance
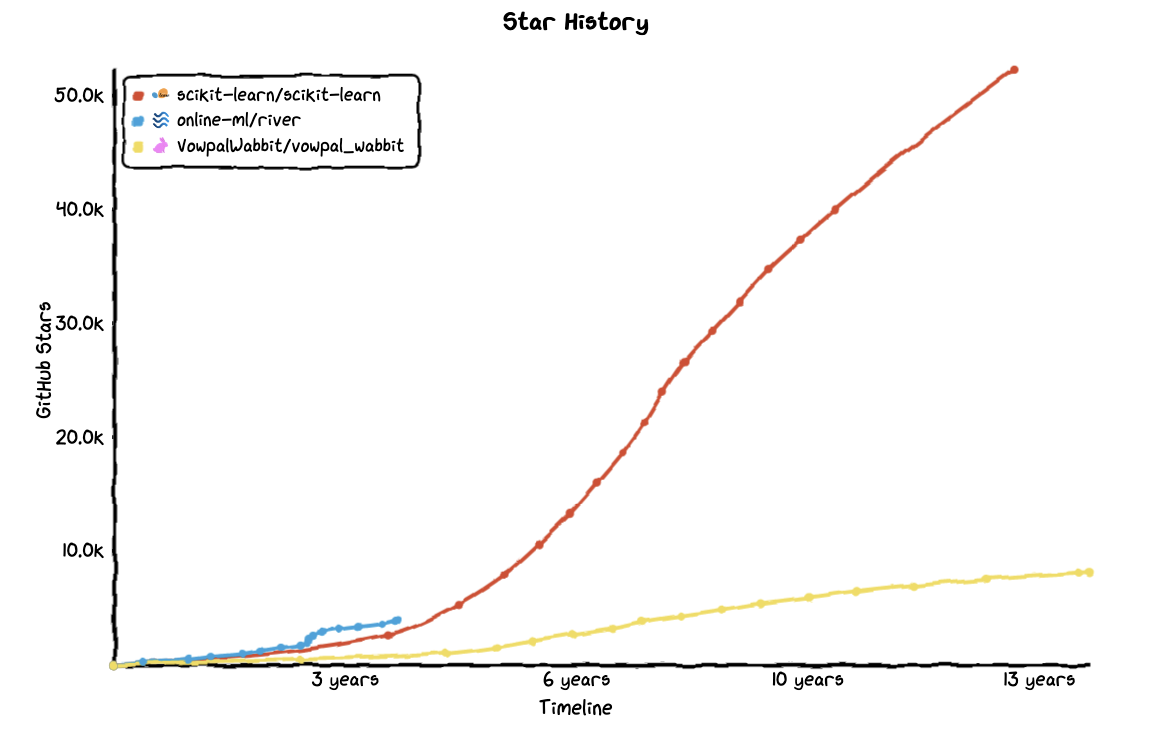
The main feedback we get about River is performance. Some people want to process gigabytes of data per second. You can’t do that with River because it’s written in Python and doesn’t make use of vectorization. Some of River’s algorithm support mini-batch updates, but that concerns a limited set of them.
We’ve had discussions about this, and have decided to work on a new library, which for now is called light-river. Our analysis is that we’re in a similar position as scikit-learn. The latter is chock-full of great machine learning implementations. And yet, in practice, many people use XGBoost and LightGBM. This is because gradient boosted trees have proven time and time again that they’re usually the best pick. Apart from explainability, why would anyone run a Naive Bayes or a linear model? In fact, even scikit-learn implemented their own flavor of LightGBM because of how good it is.
You can spend weeks trying all of the models in the world.
— Mark Tenenholtz (@marktenenholtz) November 17, 2022
Or you can just use XGBoost and focus on the data (which is what really matters).
Our belief is that a small library dedicated to performance will address this feedback we’re. By performance, we mean model accuracy as well as throughput. We also want to focus on portability, for instance by enabling models to be run in WebAssembly. Imagine being able to run an anomaly detection from within your favorite database, how cool would that be?
Essentially, we will pick a very limited subset of River, and implement it in Rust 🦀. We will begin with half-space trees, which are proving to be a very strong method for streaming anomaly detection.
Streaming MLOps
River is just a machine learning toolbox. It’s not a tool to deploy and manage machine learning models. At present, the adoption of online machine learning is hindered by the lack of dedicated MLOps tools and processes.
A long time ago, I had written a naive prototype called chantilly. It was rough, but the basic API was there. At some point, Chip Huyen offered me a job to build an online MLOps startup. It didn’t take me long to say yes, but after a few months I had to leave because it wasn’t the right setup for me. Anyway, that really got the ball rolling in my head. I have since been playing around with different ideas over the past year.
Back in April 2022, I implemented an example setup for predicting League of Legends match durations. Then I gave a talk to share my thoughts with others. With the feedback I collected, I wrote another example predicting taxi trip durations, which made heavy use of Materialize. Then I packaged that example into a piece of software called Beaver.
My goal now is to turn Beaver into a serious piece of software. In my opinion, it is filled to the brim with good ideas, but needs tender loving care to reach its full potential. Time will tell if this happens through a startup or some other commercial endeavor, or purely through open-source. Stay tuned!
Building a community
Online machine learning is merely a footnote in the grand scheme of all things AI. However, I’ve enjoyed all the interactions I’ve had with people interested in online machine learning. I’ve been wanting to connect all these people I’ve been meeting. I’ve decided to create a community of sorts called Friends of Online Machine Learning. You can find a web page with more information here. The idea is to bring together like-minded people, and altogether give online machine learning the letters of nobility it deserves.
To this end, we’ve created a Discord, which you can join here. We’re also planning to organize a retreat with the core development team to keep the good energy going. More about this later. 2023, here we come!