Do LLMs identify fonts?
Spoiler: not really
dafont.com is a wonderful website that contains a large collection of fonts. It’s more comprehensive and esoteric than Google Fonts. One of its features is a forum where users can ask for help identifying fonts – check out this poor fellow who’s been waiting for over two years and bumped his thread. I thought it would be interesting to see if an LLM could do this task, so I scraped the forum and set up a benchmark.
I implemented this as a live benchmark. By this I mean that I only ask the LLMs to identify fonts that haven’t yet been identified by the community. I evaluate the LLMs prediction by comparing it to the community’s prediction, once the latter has been made. This way, I’m sure that I’m asking the LLM to work on images it has never seen before. Indeed, there are many examples of biased LLMs that are just too good at memorizing images and text.
Benchmark contamination is a real issue in LLM evaluation, so I think it’s important to set up benchmarks this way when possible. There have been some great suggestions in this direction, including LiveBench and the Konwinski Prize
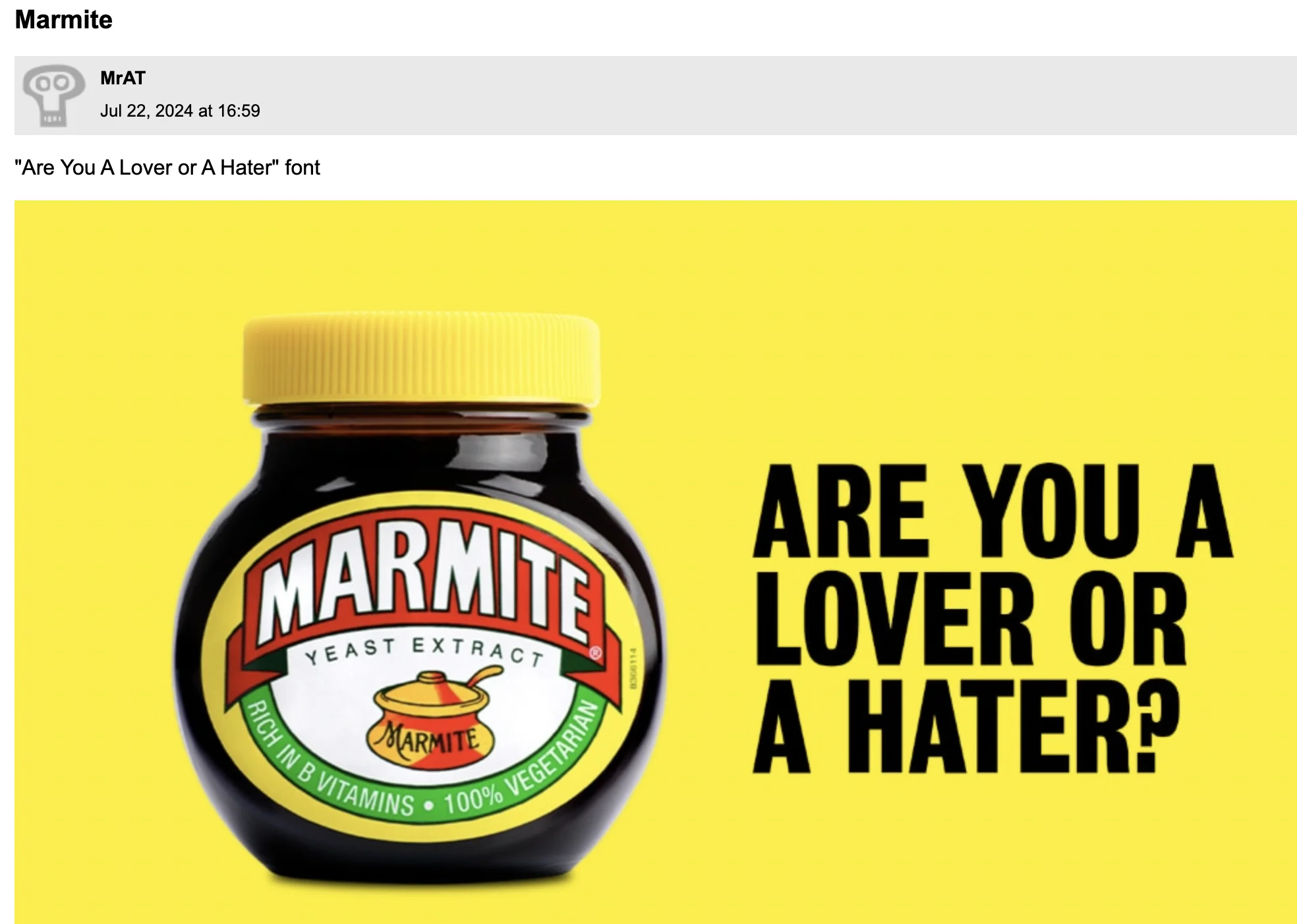
I evaluated only two LLMs: gpt-4o-mini and gemini-2.5-flash-preview-05-20. Each LLM is provided with the image uploaded by the user, the title of the thread, and a description if there is one. Providing these last two pieces of context is important, because some images contain several fonts, and the title or description may help the LLM focus on the right one. Take for instance this Marmite image:
Here are a couple extra difficult cases:
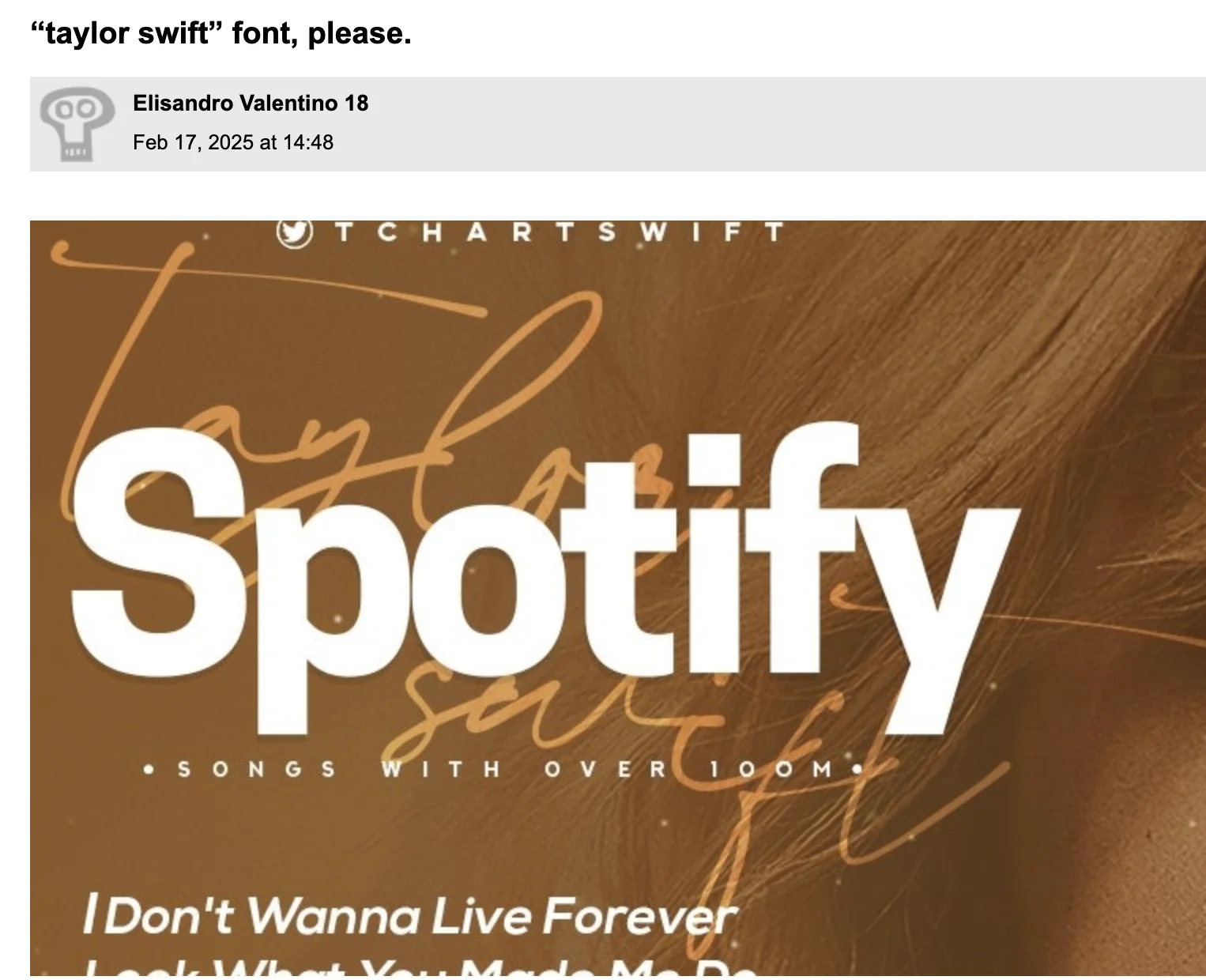
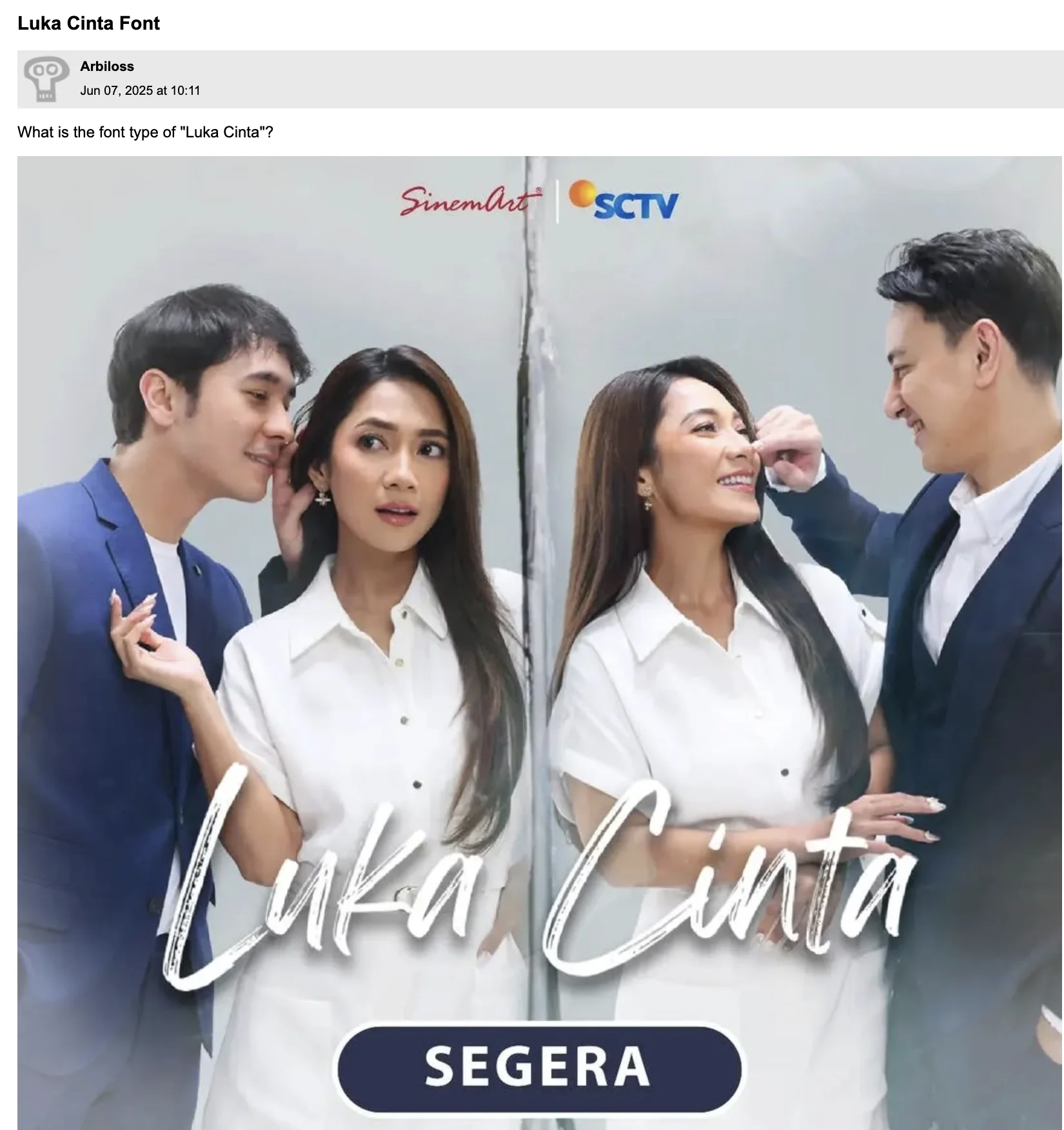
Each LLM is allowed to make up to five guesses. This allows calculating the accuracy at different levels of leniency. The performance is thus measured with a top-$k$ accuracy metric, which considers the LLM’s first $k$ guesses and checks if the correct font is among them. I ran this benchmark for a few weeks, and here are the results as of writing this recap:
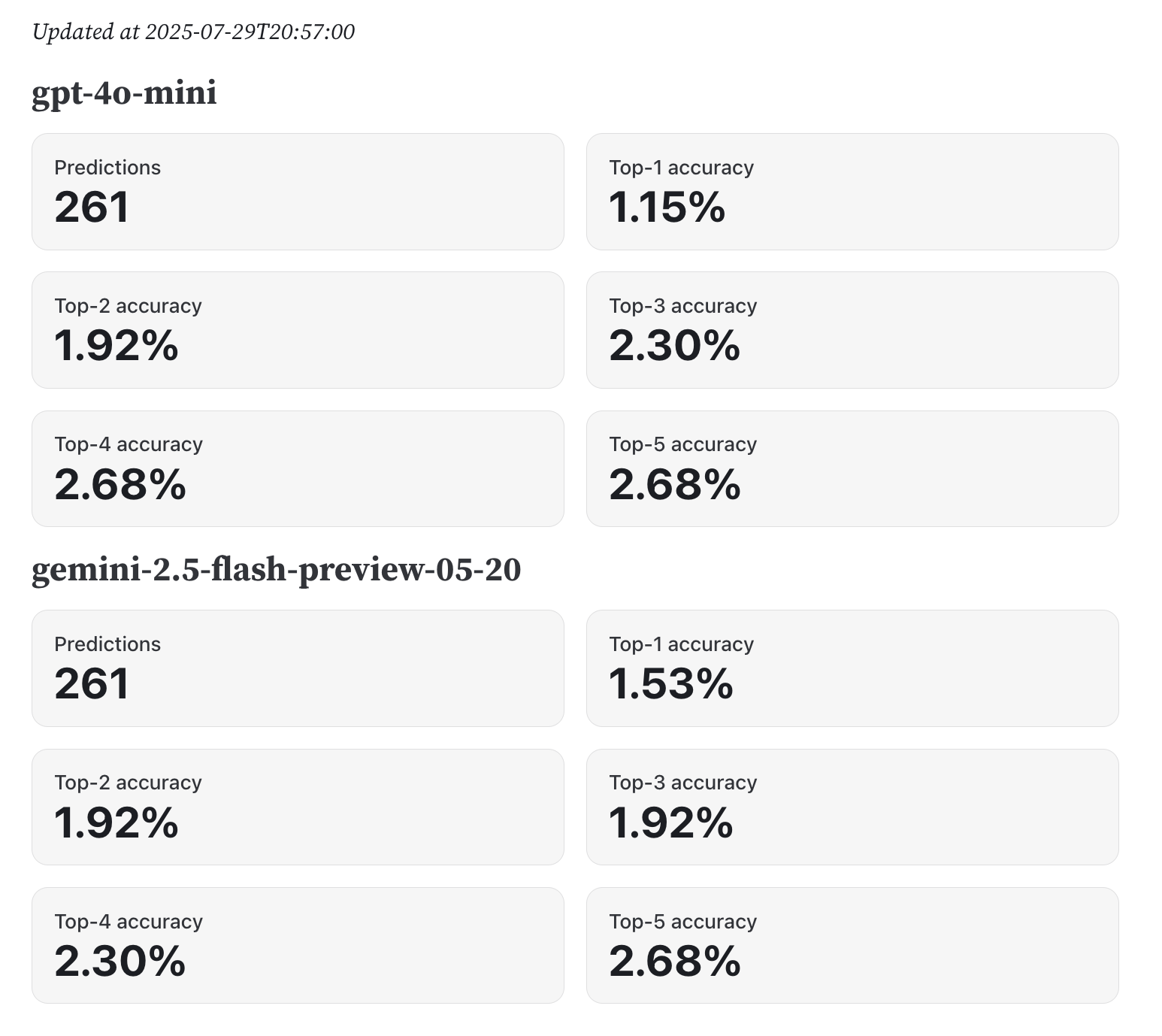
I find these results quite abysmal. It’s hard to tell whether this is because the task is too difficult, or because the LLMs is being fairly evaluated on images it’s never seen before. Answering this question would require going deeper and evaluating the LLMs on old images which it may have already seen. Anyway, I’m happy in a weird way to have found a classification task which LLMs are not good at (yet?). I think this is a good reminder that LLMs are not magic, and that they still have a long way to go before being able to solve all tasks.
Implementation notes
There’s a Python script for scraping dafont.com, and another one for prompting the LLMs. It’s the first I picked uv and it was a great experience. There’s a simple GitHub Actions workflow which runs every 3 hours. The LLM logic is written with Simon Willison’s llm package, which is super straightforward. All the results are stored in JSON files, and the benchmark is made with Observable Framework. I had been meaning to try it for a while, and I have to say it’s nice to define a dashboard with source code instead of a GUI. The live benchmark is hosted with GitHub Pages here.