A smooth approach to putting machine learning into production
Putting machine learning into production is hard. Usually I’m doubtful of such statements, but in this case I’ve never met anyone for whom everything has gone smoothly. Most data scientists might agree that there is a huge gap between their local environment and a live environment. In fact, “productionalizing” machine learning is such a complex topic that entire companies have risen to address the issue. I’m not just talking about running a gigantic grid search and finding the best model, I’m talking about putting a machine learning model live so that it actually has a positive impact on your business/project. Off the top of my head: Cubonacci, H2O, Google AutoML, Amazon Sagemaker, and DataRobot. In other words people are making money off businesses because data scientists and engineers are having a hard putting their models into production. In my opinion if a data scientist can’t put her model into production herself then something is wrong. Life should be simpler.
It’s mid-2019 and we have all these cool techniques and frameworks for learning from data. On Kaggle, the de-facto standard is to use LightGBM for “regular” competitions. As far as I understood, the top 20 competitors in the latest NLP competition all used BERT. My point is that as a community we’re getting very good at building and training extremely strong models. Not everyone is an expert, but my impression is that the average skill and knowledge of data scientists is growing at a steady pace. Differently said, we are converging towards standard practices and common patterns that are transforming machine learning into a robust technology rather than an inexact science. A good example is Martin Zinkevich’s “Rules of Machine Learning” (Martin is a research scientist at Google and has a lot of interesting things to say).
Although we are very good at building strong model, things are not so clear when it comes to putting said models into production. There might be packages for doing cutting-edge deep learning and stacking models, but you’re sort of left on your own if you want to put your model into production. I’ve been lucky enough to have met a fair amount of data science team over the past few years, and my impression is that each team has it’s own custom way of going from a local environment to a live environment. Something feels wrong.

Although each data science project I’ve encountered had it’s own unique way to go into production, generally the goal was always the same. Indeed the general idea is to extract features from a dataset, train a model, and then put the model behind an API. For making a prediction for a new instance, features are generated in real-time before being fed to the model. Every once in a while a new model is trained and replaces the current one. It’s pretty straightforward when you think about it, and is exactly what are doing all the services I mentioned above. Some people call this pattern the lambda architecture. However, down the road you might realize that is has a lot of kinks and things are no so smooth.
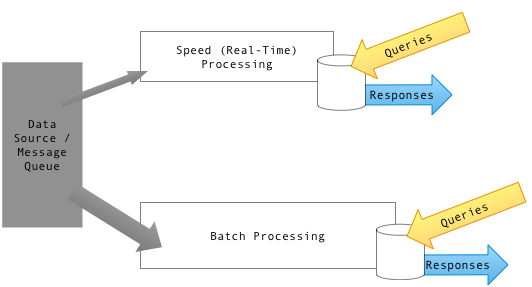
Here are a few pain points that often arise:
- The rate at which to retrain the model has to be decided upon. Should it be every day? How about every week? If it’s every week, then should it take place every Sunday at 10PM or every Tuesday at 3AM?
- You have to wait until a new model is trained in order to exploit new data. In other words, your model isn’t able to update itself every time a new observation arrives.
- Training models is going to require more and more computing power because you will have collected more and more data. You could argue that using only the data from, say, the past week is fine, but that’s also something you have to choose.
- The features you used to train your model might be difficult to generate in real-time. For example, if you’re using aggregate features then this means you need some way of storing them and retrieving them when needed. DataRobot and H2O handle some of this for you, but it is by no means a trivial task. Indeed the features are usually expected to be generated by the user beforehand.
I believe that these pain points are the reasons why a lot of machine learning projects never see the light of day. Again, putting a machine learning model is hard, which is part of the reason why good data scientists and engineers are being paid so much. The main reason why all these problems arise is because we tend to think through the lens of so-called batch learning. Indeed, we tend to think of a dataset as a rectangular dataframe composed of features X and targets y. Typically, we train a model on a training set (X_train, y_train) and predict the outcomes of a test set X_test. The issue is that in real life the situation is different. In a lot of applications, data points arrive one by one. In other words, the data is a stream and not a dataframe. On the one hand we have data arriving from a stream, and on the other hand we have static models that are meant for a batch setting. The only reason why we have to go through the pain of retraining every so often is because our models aren’t meant to handle streaming data in the first place. In my opinion, this is classic case of the hammer/nail syndrome. In this case, the hammer is the set of libraries and techniques we have in our toolbox (scikit-learn, Keras, XGBoost, etc.) whilst the nails are the problems we have to solve in real life.

Thankfully, batch learning isn’t the only paradigm that exists. There exists another subset of machine learning called online machine learning. In online machine learning, the idea is that your model is only allowed to learn from one example at a time. This is contrast to batch learning where all the available data is processed at once. Batch learning is by far the most popular of the the two regimes. I personally believe that for certain applications, online learning is a much better choice. Actually, I believe that in some cases using batch learning is wrong. However, my experience is that a big share of data scientists (especially the junior ones) are not even aware than online machine learning exists. I’ll try to give you a motivating example.
Suppose you’re building a phone application to handle bike sharing data. Your goal would be to help users to visualize and find suitable bike stations. Sometimes the users will want to take a bike, and sometimes they will want to put one back. Apparently Apple has been including this in Apple Maps for some time, a fact of which I wasn’t aware of until writing this blog post!
When a user looks at the map, they might want to find the closest bike station with at least one available bike. Likewise they might want to find one with an available space close to the destination they are heading towards. Currently, most apps tell you how many bikes and spaces are currently available. It would be nice if the app could show you an estimate of the amount of available bikes and spaces at the time you are expected to arrive. That is, how many bikes will be available in station $s$ in $m$ minutes? From a machine learning perspective, this is clearly a regression problem. Bike sharing data is freely available, meaning that anyone can have a go at this. In fact, I did exactly something like that three years ago and received a prize of 7000 euros.
Bravo à @OpenBikes_ , prix de la métropole au concours #dataconnex ions : suivez Max Halford, ca promet ;) pic.twitter.com/xa9BV9cvUT
— Gaëlle Copienne (@gcopienne) February 3, 2016
The reason why I’m mentioning myself isn’t to brag, but instead to explain what I was doing wrong and what I would have done if I did it now. When I built the app, I was but a naive undergraduate and was playing a lot around with scikit-learn. My idea was to poll bike sharing APIs from all over the world and store the amount of bikes and space of each given bike station. I polled around 25 APIs every minute or so. Then, I spent some time building a model in my nice and idyllic local environment. For simplicity I built a single global model which turned out to use approximately 20 features and a random forest. Users could use a web page and ask how many bikes or spaces would be available in a given amount of time. This basically required loading the model in memory from the disk, building the necessary features (including the weather), and make a forecast. Arbitrarily, I decided to retrain the model every Tuesday night. I had a hammer, and everything looked like a nail.
My approach worked reasonably well, but it wasn’t a smooth process to say the least. I was roughly collecting 2,000,000 events per week, which obviously imposed an increasing amount of stress during the training process. In fact, after a few months, maintaining the app on my own burned me out. It just wasn’t fun, especially considering I hadn’t planned on making any money from it, and so I took it down. The big problem for me was that putting my model into production felt really hackish, and I hate to make a lot of decisions myself. I couldn’t any find any blog post or framework which felt like they suited my needs. The biggest problem I had was generating features in real time before making a prediction. Every time a user queried my service, I had to make a prediction for a given station and a future timestamp. I was using features such as average values per hour and day, along with exponentially weighted averages of recent values. The trick is that I had to handle the logic of building these features outside of my model, mostly because things had to be handled differently in batch and in streaming mode. Nowadays I’m aware that services such as Google Cloud Dataflow and libraries like Apache Beam handle this for you, but I find them to be overly complex solutions. The crux of the problem is that I wanted to things to be simple and straightforward, not clunky and awkward.
The trick is that with online machine learning, everything is simplified. To exemplify what I mean, I’m going to use a new library I’ve been working on called creme. In creme, each model has a fit_one method. Transformers have a transform_one method, whilst classifiers and regressors have a predict_one method. Here is how you would define a model in creme:
import datetime as dt
from creme import compose
from creme import datasets
from creme import feature_extraction
from creme import linear_model
from creme import metrics
from creme import model_selection
from creme import preprocessing
from creme import stats
def add_hour(x):
... x['hour'] = x['moment'].hour
... return x
model = compose.Whitelister('clouds', 'humidity', 'pressure',
'temperature', 'wind')
model += (
... add_hour |
... feature_extraction.TargetAgg(by=['station', 'hour'], how=stats.Mean())
... )
model += feature_extraction.TargetAgg(by='station', how=stats.EWMean(0.5))
model |= preprocessing.StandardScaler()
model |= linear_model.LinearRegression(intercept_lr=0.5)
Drawing the model offers some perspective.

The convention is that each incoming observation is represented as a dict, which are usually named x. In the case of bike stations, here is an example:
{
'moment': datetime.datetime(2016, 4, 1, 0, 0, 7),
'station': 'metro-canal-du-midi',
'clouds': 75,
'description': 'light rain',
'humidity': 81,
'pressure': 1017.0,
'temperature': 6.54,
'wind': 9.3
}
The target values are usually named y, and simply are scalar values, such as 32 in case of regression and True or False for binary classification. What happens is that every time a new observation arrives, the model can be updated:
model = model.fit_one(x, y)
For making predictions, the model can be used as so:
y_pred = model.predict_one(x)
In this case, the model is a linear regression and it’s weights are updating using stochastic gradient descent. The features we are using are the raw weather metrics we have available, along with aggregates of the previous target values. I don’t want to get too specific about the details because that’s not the point of this article. What I want to convey having models that learn incrementally opens up a world of opportunities. Simply put, you don’t have to retrain models every once in a while. Your model can learn on-the-go and make predictions whenever necessary. If a new observation comes in, you can just call fit_one(x, y) and the model will be updated without having to restart from scratch. Another great benefit is that you don’t have to store the data! The only reason why the data has to be stored is because batch models learn from scratch and thus the history of the data needs to be recorded. With online machine learning, you’re allowed to discard your data as you see fit.
Online learning has been around for quite some time. Big players such as Google and Yahoo! publish many papers on the topic because it exactly suits their needs (here is a good example). Indeed, online advertising requires handling such a huge stream of data that makes batch learning out of the question. Having dynamic models that learn on the fly and that require a low amount of memory is key to the success of their operations. However, I believe that online learning doesn’t have to restricted to the world of big data. My postulate is that using online learning instead of batch learning can solve a lot headaches for small and medium projects too. Think about it: your model can update itself and make predictions right inside an HTTP request. You don’t have think about so many painful things, or pay expensive services that handle it for you.
I got an epiphany of some sorts back in January 2019, and since then have been trying to advocate online learning to my friends and colleagues. To support my arguments, I built an example app to forecast the amount of time of a League of Legends match. As of writing this article, the app is live here and you can find the code here. The goal of the project is to show how to smoothly integrate a machine learning model into a live application. Predicting the duration of a match is pretty useless, and I have little incentive to build a strong model. I mostly picked League of Legends because their API is free and has a lot of information. Also I didn’t want to work on bike stations data again.
When the application starts, a creme model is instantiated and stored inside a PostgreSQL as a pickle. Every time a user asks for the duration of a match, the app queries the League of Legends official API and retrieves the match information. Of course, if the match has already ended then nothing happens. The raw match information is then fed through the model and a predicted match duration is obtained by calling model.predict_one(match_info). Every once in a while the app polls the API to check if the match has ended. Once the match has ended, the true duration is obtained and the model is updated by calling model.fit_one(match_info, match_duration). Naturally, this requires storing the information available at the start of the match until it ends, but this isn’t very difficult to handle. That’s all there really is to it! In fact, implementing the machine learning part of the app only took me a few hours, and was rather easy to do. The following diagram somewhat summarizes what I just explained.

If I had to do the same app using, say, scikit-learn, then things would not have been as straightforward. Batch learning is great, but I feel it is a poor choice for applications where the data is by nature a stream. Of course, both approaches are complementary, and it all depends on your use case. If you’re worried about the performance of online learning models, then don’t be. Online learning models are known to converge at a very reasonable rate towards batch models. What’s more, online learning has so many benefits that in most cases it blows batch learning out of the water. I’m not saying that it’s a one-size fits all, however I do believe that data scientists and engineers should at least consider it when starting a new data science project. As I mentioned above, in my experience most practitioners are not even aware of online learning.
I hope you enjoyed this article! Feel free to send me an email if you have any questions.