Online gradient descent written in SQL
Table of contents
Edit – this post generated a few insightful comments on Hacker News. I’ve also put the code in a notebook for ease of use.
Introduction
Modern MLOps is complex because it involves too many components. You need a message bus, a stream processing engine, an API, a model store, a feature store, a monitoring service, etc. Sadly, containerisation software and the unbundling trend have encouraged an appetite for complexity. I believe MLOps shouldn’t be this complex. For instance, MLOps can be made simpler by bundling the logic into your database.
In this post, I want to push this idea, and actually implement a machine learning algorithm within a relational database, using SQL. Some databases allow doing inference with an already trained model. Actually training the model in the database would remove altogether the need for a separate inference/training service.
Being familiar with online machine learning, I picked online gradient descent. My gut feeling is that this should be a straightforward implementation using WITH RECURSIVE. I decided to work my way up to it by first implementing simpler online algorithms, starting with a running average.
Some data
To illustrate, I took some Yahoo! Finance data:
import yfinance as yf
figures = yf.download(
tickers=['AAPL'],
start='2020-01-01',
end='2022-01-01'
)
figures /= figures.std()
figures.tail()
| Date | Open | High | Low | Close | Adj Close | Volume |
|---|---|---|---|---|---|---|
| 2021-12-27 | 2.00543 | 2.06042 | 2.06425 | 2.11303 | 2.11677 | -0.7789 |
| 2021-12-28 | 2.10966 | 2.09118 | 2.11413 | 2.0777 | 2.08174 | -0.712006 |
| 2021-12-29 | 2.08148 | 2.06752 | 2.1008 | 2.08076 | 2.08477 | -0.977945 |
| 2021-12-30 | 2.08623 | 2.06549 | 2.0991 | 2.04068 | 2.04502 | -1.01873 |
| 2021-12-31 | 2.03938 | 2.0202 | 2.07074 | 2.01928 | 2.0238 | -0.950815 |
☝️ I normalized the data using standard scaling. This puts the figures on a friendlier scale. It will also help the online gradient descent converge. This could very well be done in SQL, but this is fine too.
Running average
With SQL, we could obviously just use AVG to obtain an average. We could also use a window function if we wanted to calculate the average at every point in time.
I’m not sure how common knowledge this is, but there is a formula that allows updating a running average with a new data point in $\mathcal{O}(1)$ time. This can be applied to a data stream, because the update formula only requires the current data point, as well as the current average.
$$\mu_0 = 0$$ $$\mu_{t+1} = \mu_t + \frac{x - \mu_t}{t + 1}$$
I’ll be using DuckDB. A nice feature is that it’s aware of any existing pandas dataframe – provided you’re running DuckDB using Python. Indeed, we can directly query the figures dataframe. Also, DuckDB supports WITH RECURSIVE, which is the cornerstone I’ll make heavy use of.
There are many good tutorials about how WITH RECURSIVE works, so I won’t expand on it. The way I will use it is a bit particular, in that I leverage it to update some current state. The current state points to the current row. At each recursion step, the current state is joined with the next row, which allows updating the state.
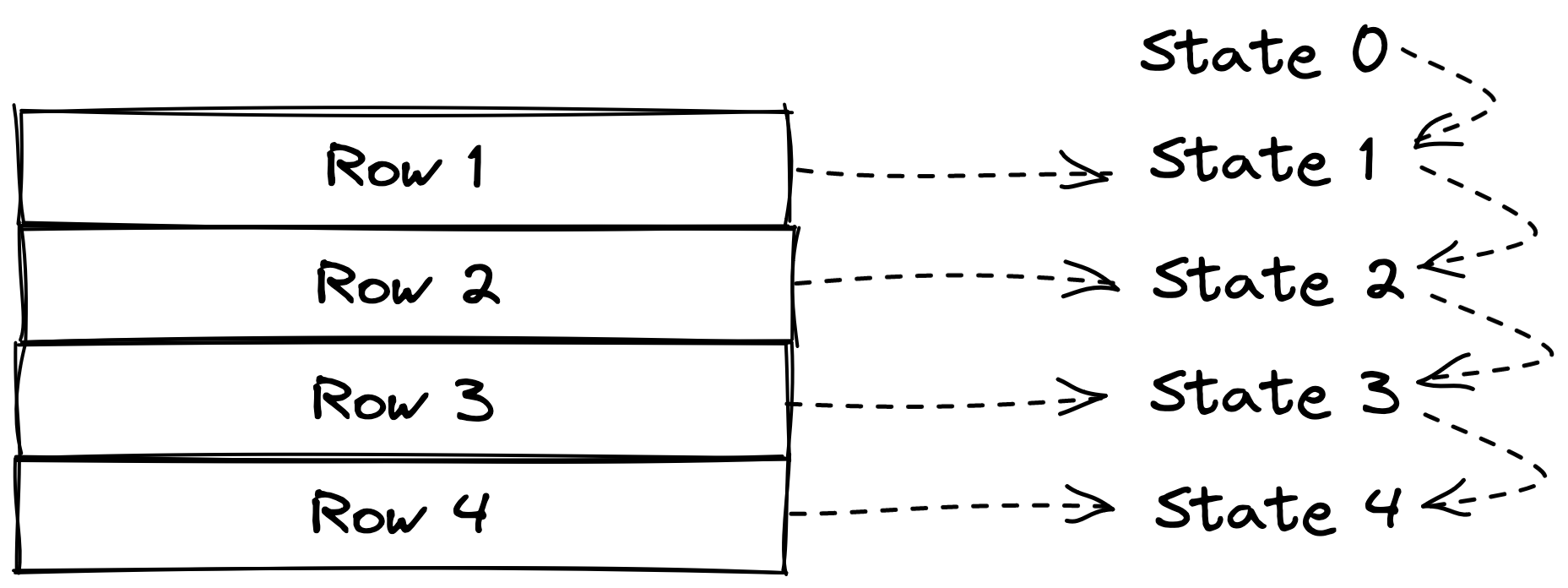
The first idea is to assign a step number to each row. Assuming the rows are pre-sorted, a ROW_NUMBER can be used to assign an auto-incrementing integer to each row. This step column is then used to connect each state to the next row.
WITH RECURSIVE
stream AS (
SELECT
ROW_NUMBER() OVER () AS step,
"Adj Close" AS x
FROM figures
),
state(step, x, avg) AS (
-- Initialize
SELECT step, x, x AS avg
FROM stream
WHERE step = 1
UNION ALL
-- Update
SELECT
stream.step,
stream.x,
state.avg + (stream.x - state.avg) / stream.step AS avg
FROM stream
INNER JOIN state ON state.step + 1 = stream.step
)
SELECT *
FROM state
ORDER BY step DESC
LIMIT 5
┌───────┬───────────────────┬────────────────────┐
│ step │ x │ avg │
│ int64 │ double │ double │
├───────┼───────────────────┼────────────────────┤
│ 505 │ 5.981568542028378 │ 3.9577706471349923 │
│ 504 │ 6.002789566151079 │ 3.953755175121315 │
│ 503 │ 6.042539700173864 │ 3.949681548101375 │
│ 502 │ 6.039508125299193 │ 3.945512507957804 │
│ 501 │ 6.074541325571636 │ 3.941332875987063 │
└───────┴───────────────────┴────────────────────┘
We can verify this is correct by doing a rolling mean in pandas:
(
figures['Adj Close']
.rolling(len(figures), min_periods=1)
.mean()
.tail()[::-1]
)
Date
2021-12-31 3.957771
2021-12-30 3.953755
2021-12-29 3.949682
2021-12-28 3.945513
2021-12-27 3.941333
☝️ This usage of WITH RECURSIVE essentially boils down to a window function. This could be implemented as such, which would avoid the headache of thinking in terms of recursion. For instance, PostgreSQL supports user-defined aggregates, which can be applied over a window. However, the WITH RECURSIVE syntax has better support across databases.
Running covariance
The query above measures the running average for a single variable – namely Adj Close. What if we want to compute something that involves more than one variable? The naive way is to just copy/paste the logic for each variable. For instance, to calculate a running covariance, it is necessary to compute the running average of two variables. Check out Welford’s algorithm for more information.
WITH RECURSIVE
stream AS (
SELECT
ROW_NUMBER() OVER () AS step,
"Adj Close" AS x,
"Close" AS y
FROM figures
),
state(step, x, x_avg, y, y_avg, cov) AS (
-- Initialize
SELECT
step,
x,
x AS x_avg,
y,
y AS y_avg,
0::DOUBLE AS cov
FROM stream
WHERE step = 1
UNION ALL
-- Update
SELECT
step,
x,
x_new_avg AS x_avg,
y,
y_new_avg AS y_avg,
cov + ((x - x_prev_avg) * (y - y_new_avg) - cov) / step AS cov
FROM (
SELECT
stream.step,
stream.x,
stream.y,
state.x_avg AS x_prev_avg,
state.x_avg + (stream.x - state.x_avg) / stream.step AS x_new_avg,
state.y_avg AS y_prev_avg,
state.y_avg + (stream.y - state.y_avg) / stream.step AS y_new_avg,
state.cov
FROM stream
INNER JOIN state ON state.step + 1 = stream.step
)
)
SELECT step, cov
FROM state
ORDER BY step DESC
LIMIT 5
┌───────┬────────────────────┐
│ step │ cov │
│ int64 │ double │
├───────┼────────────────────┤
│ 505 │ 0.9979967767965502 │
│ 504 │ 0.9918524780369538 │
│ 503 │ 0.985478504290919 │
│ 502 │ 0.9787158318485241 │
│ 501 │ 0.9719167545245742 │
└───────┴────────────────────┘
Other than handling two variables, the major difference with this query is that a subquery is used to calculate some intermediary state. We will reuse this idea for online gradient descent.
We can also verify the output is correct by comparing to pandas:
(
figures
.rolling(len(figures), min_periods=1)
.cov(ddof=0)['Adj Close']
.loc[:, 'Close']
.tail()[::-1]
)
Date
2021-12-31 0.997997
2021-12-30 0.991852
2021-12-29 0.985479
2021-12-28 0.978716
2021-12-27 0.971917
Handling many variables
The downside of the queries above is that the variable names have to be hardcoded. There is no way to handle an arbitrary number of variables. For instance, if we have several variables, how would we calculate the average of each variable, without expliciting them in the query?
As is often the case, converting the data to a tidy representation makes life easier. In this case, tidy data is obtained by melting – i.e. unpivoting – the dataframe.
figures_flat = figures.melt(ignore_index=False).reset_index()
figures_flat.columns = ['date', 'variable', 'value']
figures_flat = figures_flat.sort_values(['date', 'variable'])
figures_flat.head(10)
| date | variable | value |
|---|---|---|
| 2020-01-02 | Adj Close | -1.46542 |
| 2020-01-02 | Close | -1.46182 |
| 2020-01-02 | High | -1.49763 |
| 2020-01-02 | Low | -1.46396 |
| 2020-01-02 | Open | -1.49242 |
| 2020-01-02 | Volume | 0.180024 |
| 2020-01-03 | Adj Close | -1.48965 |
| 2020-01-03 | Close | -1.48662 |
| 2020-01-03 | High | -1.4978 |
| 2020-01-03 | Low | -1.45277 |
WITH RECURSIVE
stream AS (
SELECT RANK_DENSE() OVER (ORDER BY date) AS step, *
FROM figures_flat
ORDER BY date
),
state(step, variable, value, avg) AS (
-- Initialize
SELECT step, variable, value, value AS avg
FROM stream
WHERE step = 1
UNION ALL
-- Update
SELECT
stream.step,
stream.variable,
stream.value,
state.avg + (stream.value - state.avg) / stream.step AS avg
FROM stream
INNER JOIN state ON
state.step + 1 = stream.step AND
state.variable = stream.variable
)
SELECT *
FROM state
WHERE step = (SELECT MAX(step) FROM state)
ORDER BY variable
┌───────┬───────────┬────────────────────┬────────────────────┐
│ step │ variable │ value │ avg │
│ int64 │ varchar │ double │ double │
├───────┼───────────┼────────────────────┼────────────────────┤
│ 505 │ Adj Close │ 5.981568542028378 │ 3.9577706471349923 │
│ 505 │ Close │ 6.03165394229666 │ 4.012373756823449 │
│ 505 │ High │ 6.057853942108038 │ 4.03765319364954 │
│ 505 │ Low │ 6.05591789308585 │ 3.985178489614261 │
│ 505 │ Open │ 6.046125216781687 │ 4.006746251814558 │
│ 505 │ Volume │ 1.0143664144585565 │ 1.9651814487272024 │
└───────┴───────────┴────────────────────┴────────────────────┘
The main difference with the first query is that the join condition in the recursion includes the variable name, as well as the step number. A RANK_DENSE statement is also used instead of ROW_NUMBER to assign a step number to each group of rows.
Here is the equivalent using pandas:
(
figures_flat
.groupby('variable')['value']
.rolling(len(figures_flat), min_periods=1)
.mean()
.groupby('variable')
.tail(1)[::-1].sort_index()
)
variable
Adj Close 3.957771
Close 4.012374
High 4.037653
Low 3.985178
Open 4.006746
Volume 1.965181
Online gradient descent
Finally, we have enough experience to implement online gradient descent. To keep things simple, we will use a very vanilla version:
- Constant learning rate, as opposed to a schedule.
- Single epoch, we only do one pass on the data.
- Not stochastic: the rows are not shuffled.
- Squared loss, which is the standard loss for regression.
- No gradient clipping.
- No weight regularisation.
- No intercept term.
None of these are impossible to implement using SQL. I just thought I’d keep things simple in order to keep the code digest. Anyway, these assumptions lead to the following update formulas:
$$p_t = \dot{w}_t \cdot \dot{x}_t$$
$$l_t = p_t - y_t$$
$$\dot{g}_t = l_t \dot{x}_t$$
$$\dot{w}_{t+1} = \dot{w}_t - \eta \dot{g}_t$$
I’ve added a $\dot{}$ symbol to the vector variables. Therefore $p_t$ is the prediction, defined as the dot product between weights $\dot{w}_t$ and features $\dot{x}_t$. The gradient of the loss $l_t$ is used to obtain the error gradient for the features $\dot{g}_t$, which respect to the current weights. This all leads to the simple weight update formula $\dot{w}_t - \eta \dot{g}_t$.
As an example, I decided to predict the Adj Close variable using the other variables. I’m not saying this makes a lot of sense, it’s just for the sake of example.
WITH RECURSIVE
X AS (
SELECT
RANK_DENSE() OVER (ORDER BY date) AS step, *
FROM figures_flat
WHERE variable != 'Adj Close'
ORDER BY date
),
y AS (
SELECT
RANK_DENSE() OVER (ORDER BY date) AS step, *
FROM figures_flat
WHERE variable = 'Adj Close'
ORDER BY date
),
stream AS (
SELECT X.*, y.value AS target
FROM X
INNER JOIN y ON X.step = y.step
),
state AS (
-- Initialize
SELECT
step,
target,
variable,
value,
0::DOUBLE AS weight,
0::DOUBLE AS prediction
FROM stream
WHERE step = 1
UNION ALL
-- Update
SELECT
step,
target,
variable,
value,
weight,
SUM(weight * value) OVER () AS prediction
FROM (
SELECT
stream.step,
stream.target,
stream.variable,
stream.value,
state.prediction - state.target AS loss_gradient,
loss_gradient * state.value AS gradient,
state.weight - 0.01 * gradient AS weight
FROM stream
INNER JOIN state ON
state.step + 1 = stream.step AND
state.variable = stream.variable
)
)
SELECT *
FROM state
WHERE step = (SELECT MAX(step) FROM state)
ORDER BY variable
┌───────┬──────────┬──────────────────────┬───────────────────┬───────────────────┐
│ step │ variable │ weight │ target │ prediction │
│ int64 │ varchar │ double │ double │ double │
├───────┼──────────┼──────────────────────┼───────────────────┼───────────────────┤
│ 505 │ Close │ 0.2511547716803354 │ 5.981568542028378 │ 5.938875441702928 │
│ 505 │ High │ 0.24043897039853313 │ 5.981568542028378 │ 5.938875441702928 │
│ 505 │ Low │ 0.2447191283620627 │ 5.981568542028378 │ 5.938875441702928 │
│ 505 │ Open │ 0.23603830762609726 │ 5.981568542028378 │ 5.938875441702928 │
│ 505 │ Volume │ 0.057510279698874206 │ 5.981568542028378 │ 5.938875441702928 │
└───────┴──────────┴──────────────────────┴───────────────────┴───────────────────┘
It seems to be working! How can we check it is correct though? Well, we can fit an instance of scikit-learn’s SGDRegressor. The weights should correspond exactly to what we obtained in SQL, as long we provide the correct parameters. This is to align with the simplifying assumptions that were made in the SQL implementation.
from pprint import pprint
from sklearn import linear_model
model = linear_model.SGDRegressor(
loss='squared_error',
penalty=None,
fit_intercept=False,
learning_rate='constant',
eta0=0.01,
max_iter=1,
shuffle=False
)
X = figures[:-1].copy()
y = X.pop('Adj Close')
model = model.fit(X, y)
pprint(dict(zip(X.columns, model.coef_)))
{'Close': 0.2511547716803354,
'High': 0.2404389703985331,
'Low': 0.2447191283620624,
'Open': 0.23603830762609757,
'Volume': 0.05751027969887417}
Spot on! To be even more certain this is correct, we can compare with River’s linear regression implementation, which uses online gradient descent under the hood.
from river import linear_model
from river import optim
class CustomSquaredLoss:
def gradient(self, y_true, y_pred):
return y_pred - y_true
model = linear_model.LinearRegression(
optimizer=optim.SGD(lr=0.01),
loss=CustomSquaredLoss(),
intercept_lr=0.0,
l2=0.0
)
for i, x in enumerate(figures[:-1].to_dict(orient='records')):
y = x.pop('Adj Close')
model.learn_one(x, y)
pprint(model.weights)
{'Close': 0.2511547716803356,
'High': 0.2404389703985331,
'Low': 0.24471912836206253,
'Open': 0.2360383076260972,
'Volume': 0.057510279698874255}
Conclusion
A machine learning algorithm which can be trained using SQL opens a world of possibilities. The model and the data live in the same space. This is as simple as it gets in terms of architecture. Basically, you only need a database which runs SQL.
Of course, the implementation we made is quite basic. Moreover, models using online gradient descent aren’t necessarily the strongest ones. However, one could argue that what matters most in a model are the features you feed it with. As such, online gradient descent done in the database can be a great baseline from which to start with.
The key advantage of online machine learning is that you don’t need to revisit past data points to update a model. However, all the queries we’ve written are stateless, and will run from the top when they are refreshed. This sort of defeats the purpose of doing things online. Thankfully, stream processing engines are popping up, and they usually provide an SQL interface. For instance, Materialize is working on providing WITH RECURSIVE semantics. Doing online gradient descent on top of Materialize sounds very powerful to me.