One year at Alan
Table of contents
Context
Today marks the 1 year anniversary since I started working at Alan. It’s my first real job, and certainly the place where I grew up the most professionally. I’m writing this post to summarise what I did and what I learnt at Alan.
Alan is a special company. It has a unique culture that is starting to become famous in France. I won’t expand on the way things work at Alan, and will simply focus on the way I experienced it. Let me just say this: it works. The pace at which stuff gets shipped is insane. And yet, it’s a healthy environment to be working in. Alaners are some of the kindest and wisest human beings I’ve had the chance to meet.
What I (mostly) did
Becoming the “document processing guy”
At first I performed “woodchuck” tasks. These had been prepared before I arrived so that I could onboard smoothly. I worked on some acquisition cost stuff that I didn’t really enjoy that much. After a couple of months I noticed that the engineering team was hitting a roadblock in terms of document processing. I thought it was a really interesting topic and offered to work on it. I eventually became “the document processing guy”. I mostly worked on document processing during the rest of this year at Alan.
Being a health insurance company, Alan has to process tens of thousands of health insurance documents every week. Our users send us thousands of documents every day: quotes, invoices, justifications, contracts, prescriptions, etc. Most of these documents are processed manually. This costs a five digit figure every week, and is by far the highest operational cost. The cost scales linearly with the size of the memberbase. And obviously Alan is relatively small right now, with roughly 200k members.
After a year, with the current memberbase, I estimate that I’m saving Alan an extra ~3000 euros per week. >30% of documents are now being processed fully automatically, versus 15% when I arrived. I know this because I built a dashboard to track our costs, and estimate the time – and thus euros – saved by our automated document processing initiatives.
It’s definitely motivating to work on a concrete project with a tangible performance measure. I knew very quickly if the code I pushed into production had an impact or not. Sometimes it could be demoralising when the overall automation rate dropped from one week to the other. But overall things went well and I’m satisfied with the impact I had.
Automated document processing is non-trivial
The goal of document processing is to extract structured information from files uploaded by users. This is usually done by manual operators – i.e. human beings. The goal of automated document processing is to translate an operator’s human logic into code. Easier said than done 🙃
At Alan this is really straightforward in terms of code structure. The input I’m given is a bunch of bytes. The expected output is a Python dataclass. This output is then consumed by engineers to determine how much a user should be reimbursed. My scope was thus to write the logic to go from a document to structured information. I rarely had to handle the communication with the web/mobile app and the database.
Although it is straightforward to explain, automated document processing is extremely fickle to implement. If you’re lucky, you’re dealing with standard documents that always follow the same template. You can write some deterministic logic if that’s the case. It either works or it doesn’t.
The issue at Alan is that we’re dealing with heterogenous documents uploaded by users. Sometimes these can be clean PDFs, but very often it’s rotated and distorted images taken from a mobile phone. The documents I dealt with came from all over France and never followed the same template.
The goal was therefore to implement logic that worked well on average. In particular, the goal was to produce a high precision – i.e. documents which are processed correctly – and a decent recall – i.e. the automation rate: the share of documents where no human intervention is required.
In my experience, document processing tasks can be compared in terms of difficulty across 3 dimensions:
- Structured vs. unstructured — the pieces of information in the document may be related to each other in some way. For instance, processing a document might require to recognise a table with columns, rows, and cells. This is different than unstructured documents, where the information isn’t necessarily related. For instance we might be looking for a date and a currency amount, regardless of where that information is in the text.
- Handwritten vs. printed — obviously handwritten documents are more difficult to process than printed documents. In particular, PDF files with printed characters are easier to process because you don’t need an OCR, and can instead use tools like PDFMiner. Some documents are mixed: part of the information is printed, while the rest is filled in with handwriting.
- Homogenous vs. heterogenous — A document processing task usually has limited perimeter. For instance, at Alan I wrote some bespoke logic to handle glasses prescriptions. If you’re lucky, documents in this category will follow a template. This makes them much easier to process, mainly because you know beforehand where the different parts of information are supposed to be located.
Here’s a table of different document processing situations in increasing order of difficulty. I’ve put an 👽 emoji for cases which I haven’t encountered, but which I imagine would be quite difficult.
| Unstructured | Printed | Homogenous | Difficulty | Example |
|---|---|---|---|---|
| ✅ | ✅ | ✅ | 😁 | Standardized invoices |
| ✅ | ✅ | ❌ | 😄 | Printed invoices |
| ❌ | ✅ | ✅ | 😬 | Dental quotes |
| ✅ | ❌ | ❌ | 😣 | Handwritten invoices |
| ❌ | ✅ | ❌ | 🥵 | Arbitrary quotes |
| ❌ | ❌ | ❌ | 🤬 | Medical prescription note |
| ❌ | ❌ | ✅ | 👽 | |
| ✅ | ❌ | ✅ | 👽 |
Naturally, it makes sense to want to automate documents which are both abundant and easy to process. But usually these also turn out to be the ones that take the less time to process by a human being. Therefore it might not be worth putting engineering effort into automating these “easy” documents.
Deciding which documents to automate really depends on what is the end goal. Is it to increase the automation rate in order to increase the user experience? Or is it to reduce the total number of human working hours required per week?
Obviously, the end goal is to automate the processing of all documents. But that’s a bit of a utopia, which some stakeholders never seemed to understand 😅. Every so often, in order to prioritize my efforts, I took a step back to measure the volume and difficulty of the documents we were receiving. At the end of the day, I was mostly the one deciding what I wanted to work on. I had to draw a fine line between having impact quickly and doing deep work on difficult documents.
Processing dental quotes
I was first tasked with automating the processing of dental quotes. This turned out to be the north face: these are some of the most difficult kind of documents to process. I had never document processing before, so this was my first rodeo. Essentially, the information of a quote is contained in a table. The first goal is to recognise these tables. Once that’s done it’s pretty straightforward to write business logic to handle them.
At first I didn’t want to reinvent the wheel. I looked into using Amazon Textract’s table extraction tool. Obviously, it would have been too good to be true if it just worked. Spoiler: it didn’t. The documents we receive were simply of too poor quality to be processed by Textract correctly. Textract works fine for PDFs, but struggles for images with distortions. Sadly, these are all too common in user uploads.
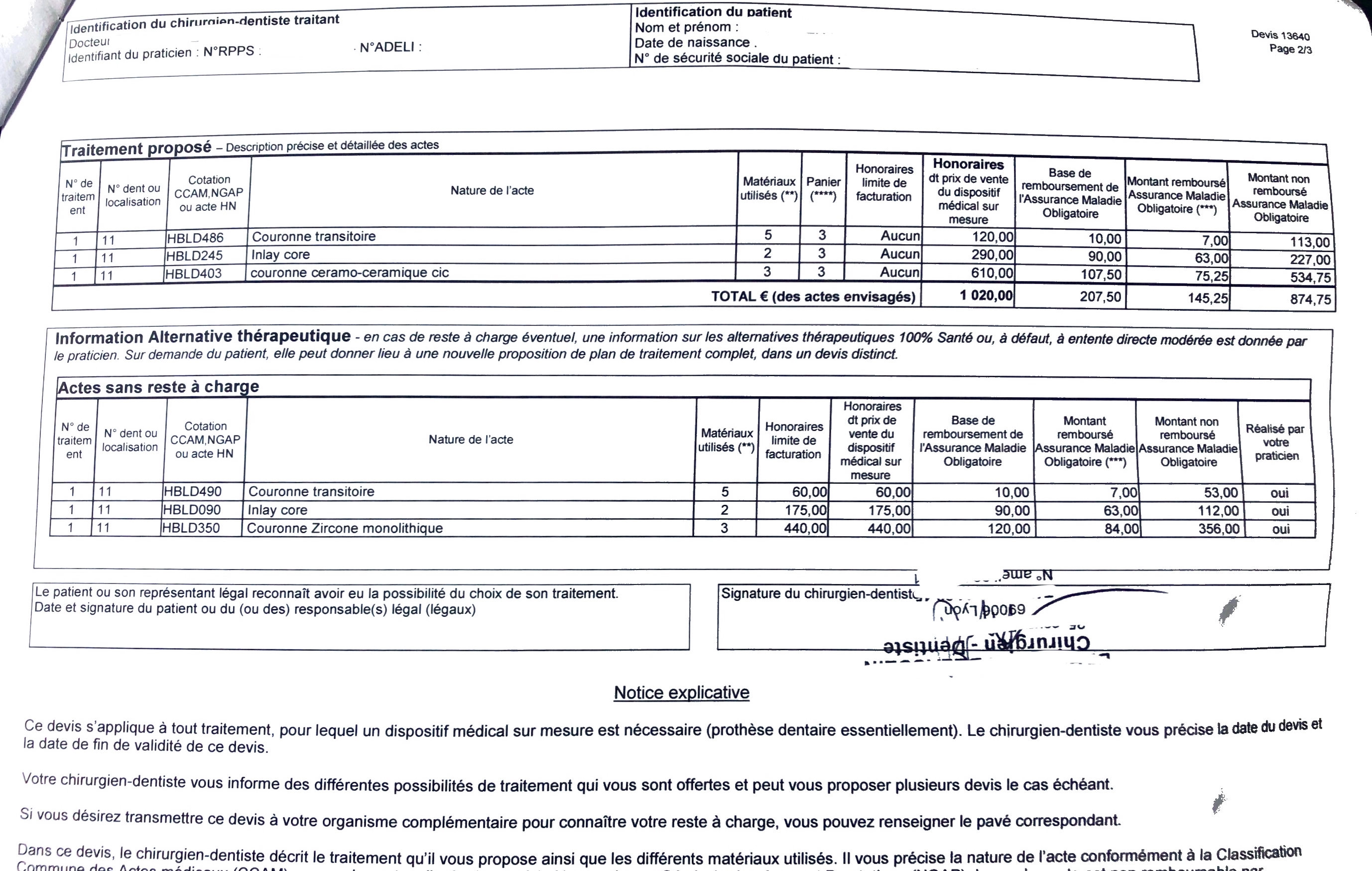
This one is of rather high quality.
I decided to get my hands dirty and implement my own logic to extract tables from a document. I simplified the problem by instead focusing on extracting lines from a document. I decided to start from the output of an OCR. I wrote some logic to group text bounding boxes into lines. This is called line segmentation, and is a special of document layout analysis. As it turns out, this is still an open problem with no best in class solution. There’s a ton of litterature on line segmentation. I suggest checking out this relatively recent paper which provides some nice visualizations. This one is pretty cool too.
In the end I implemented my own algorithm. I formulated the problem as an assignment problem between bounding boxes. I’ll skip the details here, but I might elaborate in another blog post. Anyway, I eventually reached a point where the line segmentation algorithm was working in ~50% of cases. I had to do a bunch of gambiarra to get there, such as implementing my own deskewing logic. Overall, I was quite disappointed by the lack of good open-source libraries in this area. Recently there’s LayoutParser that arrived in town, but it’s still a bit too experimental to my taste.
I would say that this is the project where I was the least successful. It was really difficult as a first task. Looking back, I should have started with something simpler. That would have given me more time to think about the problem, rather than diving into a scrappy solution. I couldn’t justify spending months on this problem without producing any results, especially as a newcomer. So I produced something that worked for dental quotes in ~30% of cases. It’s not bad, but I’m pretty sure that ~80% of quotes could be automated with some more work.
Classifying documents
I spent a lot of time in the existing codebase while working on dental quotes. I noticed that there was rudimentary logic to classify documents into categories – quotes, invoices, prescriptions, etc. This logic was essentially a bunch of regex patterns. I assumed they worked fine because nobody challenged them. Still, I was curious about their performance. I build a training set of documents that were processed by our manual operators. Measuring the performance of this rule-based classification system revealed that it was not doing very well.
When you do document processing, in order to determine what parsing logic to apply, the first step is to classify a document. Indeed, the parsing logic for a quote is not the same as for an invoice. Being very good at classifying documents is of paramount importance. And it’s not rocket science: most document categories can in fact be determined just by looking at the text contents returned by an OCR.
I saw that there was an opportunity to replace the rule-based system with a machine learning algorithm. I benchmarked a plain and simply scikit-learn pipeline. It turned out to be excellent. I packaged the training logic into a simple function that I integrated into the backend code. The model isn’t deployed: it’s just a pickle file that is loaded when the app starts. I stripped the model so that it doesn’t consume a lot of RAM. I wrote about this in a previous article.
Processing invoices (and prescriptions)
The majority of documents a (French) health insurance company have to process are invoices. These can originate from pharmacies, dentists, opticians, psychiatrists, etc. In France, a lot of these invoices are reimbursed by the national health insurance, and it mostly happens automatically. But some invoices are not reimbursed in such a way. This is the case for osteopathy consultations, because they’re not considered as essential healthcare. In this case, users need to send their osteopathy invoices to their private health insurance.
We receive over a thousand of these invoices every day. They only take a few minutes to process manually. They’re not as time consuming as, say, dental quotes. However, we receive a lot of them, so automating them creates a delightful experience for many users. Indeed, if we can process invoices straight away, we can reimburse users extremely quickly. This makes them really happy, and sometimes they share that with us.
Processing invoices is more straightforward than processing quotes. I started to work on osteopathy invoices, because they represented the largest chunk of invoices we receive. There were four pieces of information to find in each document:
- The date the care took place.
- The amount of money it cost.
- The health practitioner which performed the care. French medical invoices usually contain an ADELI number which identifies the health practitioner.
- The name of the patient who received the care. We know who uploads a document. So we know that the patient is someone in the family of the person who did the upload. Therefore we know what names we’re looking for in the document.
It doesn’t matter where the information is in the document. Therefore, this information can just be extracted from the text transcription of an invoice. Basically, this may be done by implementing extractors which are responsible for finding particular pieces of information. For instance, I wrote one extractor to look for dates, and another one to search for currency amounts.
The way I framed it, each extractor first generates a list of candidates. For example, there might be more than one date in an invoice, so listing them all in the first place is necessary. There’s then another piece of logic to determine the most relevant candidate. In the case of osteopathy invoices, the rule was that the cost is always a round number between 35 and 90 euros. For dates, taking the most recent date usually worked. Naturally, making these decisions with a supervised learning algorithm is preferable. But I first started with a rule-based system to ship something quickly.
A big challenge was dealing with character recognition mistakes. Modern OCRs usually possess a character correction layer. The latter is biased in that it only works well on the corpuses it has been trained on. The commercial OCRs I used did not do well at recognising dates, currency amounts, and identifiers from the French health system. I spent a decent amount of time at implementing my own character correction algorithms, following Peter Norvig’s seminal post on the topic. I would first generate a list of tokens that looked like a date, allowing for mistakes. I would then generate candidates by replacing/removing/adding characters and only keep those that actually looked like valid dates. These filtered candidates would then go through the candidate selection system I described in the previous paragraph.
Processing invoices was really fun. I got a long way by formalising it as an entity recognition problem. Indeed, instead of writing a bunch of regex rules, I focused on separating the candidate generation logic from the candidate selection logic. This allowed me to reuse pieces of logic across different types of invoices. I was also able to reuse some logic across document categories. For instance, I reused the date parser I developed when working on invoices for pharmacy prescriptions. There’s this paper from Google which is very resemblant to what I did at Alan, albeit at a smaller scale. I also summarised my work on invoices in this article.
It’s apparent to me now that there is still a lot of work to be done in this field. Extracting information from documents is a difficult task because a lot of logic is specific to a particular task a company may have. It is therefore difficult to develop generic models that work out of the box. Models have to be fine-tuned. Datasets are messy. It feels to me like there are some important building blocks that are missing from the open-source landscape. There are many topics I would like to work on in the future, in particular those related to character recognition mistakes.
Refactoring code
Some document processing work had already been done when I joined Alan. There was some existing document processing logic in the codebase. It felt to me that this code was very ad-hoc. It was written in a scrappy way to get things done. That’s fine! But as I was adding logic to implement more and more different kinds of documents, I felt like I had to take a step back to refactor parts of the codebase.
I put a lot of love into our document processing logic. I treated it as one of my own projects, which for me was important. I write better code and put more intent into its design when I have ownership over it. Being labelled as the document processing guy encouraged to go deep into the codebase and challenge design decisions that had been made by my predecessors.
I unified the way we extract text from documents – I call that transcribing. I introduced an interface so that regardless of the document source – PDFs, images, word documents – the ensuing data structure was always the same. This vastly simplified some of the codebase, and eased the introduction of new document processors.
I clarified the interfaces between the document processing logic and what we call the claim engine – basically the machinery that determines how much money to reimbursed our members. Instead of just returning a dataclass with the structured information, each document processor also returns the location of each piece of information in the text. I did a bunch of other things too, which taken individually didn’t look like much, but which I believe were much appreciated by our engineering team. I’m really a nerd for clean code so I enjoyed doing this very much.
The last thing I did in this regard was to introduce a clear nomenclature. Setting in stone notions such as “categories” – invoices, prescriptions, quotes, etc. – as well as “labels” – osteopathy, dental, optics, etc. – really helped. Documenting simple sentences went a long way to ease the communication with other people:
- A
Transcriberproduces aTranscription. - A
Transcriptionis a list ofPages. - A
Pageis a list ofWords. - A
Wordis a(str, BoundingBox)tuple. - A
BoundingBoxis a list of fourPoints. - A
Pointis a(float, float)tuple.
I felt like it was a perfect case of the Rumplestilskin principle. It may not seem like much, but once these concepts and relationships were introduced, the code flowed in a more natural way.
Processing competitor contracts
I spent most of my time processing health insurance documents. But Alan also has to process another kind of documents: health insurance contracts. These are usually PDF files which list the amount of money a health insurance company reimburses for a bunch of health guarantees. For instance, the contract might say that it reimburses up to 50 euros every time you go to the dentist.
There is no standard protocol to express health insurance guarantees. The Alan guarantees are quite straightforward, as you can see here. This isn’t always the case for our competitors. Some of our competitors are dinosaurs and express stuff in a very user-unfriendly manner.
Members of the Alan Sales team are responsible for translating a competitor health insurance contract into a list of Alan guarantees. This enables our Insurance team to determine if we are competitive, and what kind of pricing we should offer. This translation process can take well over an hour and is error-prone. It’s rather important to do this well, because this information becomes legally binding, as it determines how much money we will reimburse.
I worked on an automated contract translator during a 3 days hackathon. The project was rather successful – I even won some Alan socks 🧦! I have therefore been working for the past few months on industrialising this proof of concept. I don’t feel like elaborating on the details in this article. In a nutshell, once a PDF contract was parsed into a list of guarantees, the goal was to map these competitor guarantees to Alan guarantees, which I framed as a variant of the stable marriage problem.
Monitoring processing performance
It’s crucial to monitor the performance of any document processing system. As I said, document processing is not a deterministic process. I built some historical datasets to guide the development of documenting processing logic. This allowed me to measure performance in an offline manner. However, you also need some way to monitor how well you’re doing in production. You can’t just cross your fingers and run with your eyes closed. At Alan, we send a sample of the documents to manual processing, even though the bot managed to handle them. This allows to estimate the bot’s overall performance.
I had quite a lot of fun working on this monitoring aspect. It was crucial to get this right to convince stakeholders that it was actually working and worthwhile. By the end of my first year at Alan, I’m able to estimate how much money our document processing logic is saving us. Under the hood, I built some prepared data so that the business logic is versioned in our codebase, and not in the dashboard.
Sharing knowledge
Beyond shipping stuff, I very much enjoy sharing what I work on. I worked on arguably a rather niche topic. Document processing isn’t everyone’s cup to tea, and is definitely a topic with a researchy aspect to it. There’s a rather high learning curve to climb before being able to have an impact. Reducing the bus factor matters to me very much. Therefore I didn’t want to become a bottleneck, and made a conscious effort to document what I was doing along the way. This happened through different mediums: writing a couple of blog posts, writing comprehensive code comments, doing internal presentations, and writing documentation in our Notion space.
The lessons I learned
Alan is a really great place to learn, especially when you’re a junior. There are a few simple yet important ideas that resonated with me.
SQL is (usually) enough for analytics
I had a fair bit of SQL at university. In fact, I taught SQL classes during my PhD. However, I’ve been using exclusively Python when doing data science. When I have to process data, my reflex is to write a Python script where the first line of code usually imports pandas. I naively assumed that most of the data processing pipelines at Alan would be written in Python.
It turns out that the vast majority of data processing at Alan is done in SQL! Python is just used to import data from third-parties and dump into our warehouse. When I arrived, our warehouse was a PostgreSQL instance. We migrated Snowflake in early 2021. And boy oh boy is it powerful; to the point where, I’m not convinced we still need tools like Spark, Ray, Dask, and Vaex.
Simple machine learning goes a long way
We never did any deep learning. My bread and butter was scikit-learn’s LogisticRegression. I was able to replace several rule-based systems with a scikit-learn pipeline. Of course, there are opportunities at Alan to use complex models to reach state-of-the-art performance, but that’s not our mindset. The goal is to ship simple implementation that have an impact in a short amount of time.
Stakeholders should consume datasets, not dashboards
This is my own personal opinion. There were a few times where I was asked to build a dashboard for a stakeholder. I really thought this was silly. Instead of giving the stakeholder fish, I wanted to teach them how to fish. Instead of giving them a dashboard, I wanted to give them a dataset and ask them to build the dashboard themselves. I felt like this would 1) empower them by giving them the flexibility to edit the dashboard by themselves 2) save me some time and allow me to focus on the data processing.
Full-stack data roles enable more impact
At Alan, people are expected to have a full-stack skillset. A good example are Alan engineers: they’re supposed to be capable of writing backend code as well as frontend code, for both web and mobile. This idea goes beyond the skillset: you’re supposed to have a full-stack mindset too. For instance, everyone is expected to “own” the feature they’re working on. There are of course product managers, but no product owners.
This full-stack approach also applies to members of Alan’s data team. We aren’t labelled as scientists, analysts, or engineers: we were expected to be capable on each aspect. Therefore, we are all able to deliver a project from A to Z by ourselves. I very much enjoy this way of working. When I worked on a new document classification model, I started by opening a notebook. I took care of grabbing training data from the warehouse. I owned the model deployment aspect. I didn’t have to ask a data engineer to give me a hand, so there was no friction. I thought that this was wonderful and that it made me very efficient.
I’m really bullish on having full-stack “data” people. I think that something is wrong if the technical stack is so complicated that you need a data engineer. Likewise, I believe that a good data scientist should also be good data analyst, because I feel like they need as much business acumen as an analyst to be impactful. Obviously, the downside to this approach is that it makes recruitment difficult. Alan often refuses strong candidates because they are lacking on either side of spectrum.