Online active learning in 80 lines of Python
Active learning is a way to get humans to label data efficiently. A good active learning strategy minimizes the number of necessary labels, while maximizing a model’s performance. This usually works by focusing on samples where the model is unsure of its prediction.
In a batch setting, the model is periodically retrained to learn from the freshly labeled samples. However, the training time is usually too prohibitive for this to happen each time a new label is provided. This isn’t the case with online models, because they are able to learn one sample at a time. Active and online learning naturally fit together.
In an online setting, active learning can also be used to accelerate training. The idea of online active learning is to loop through every sample in a dataset, make a prediction, and then decide whether the model should be updated or not. Therefore, given a labeled dataset, online active learning provides a way to trade between model accuracy and training speed.
I recently implemented a basic version of online active learning in River – see the pull request. I decided to build a quick spam classifier demo with Streamlit to showcase this. The demo should be available at this link.
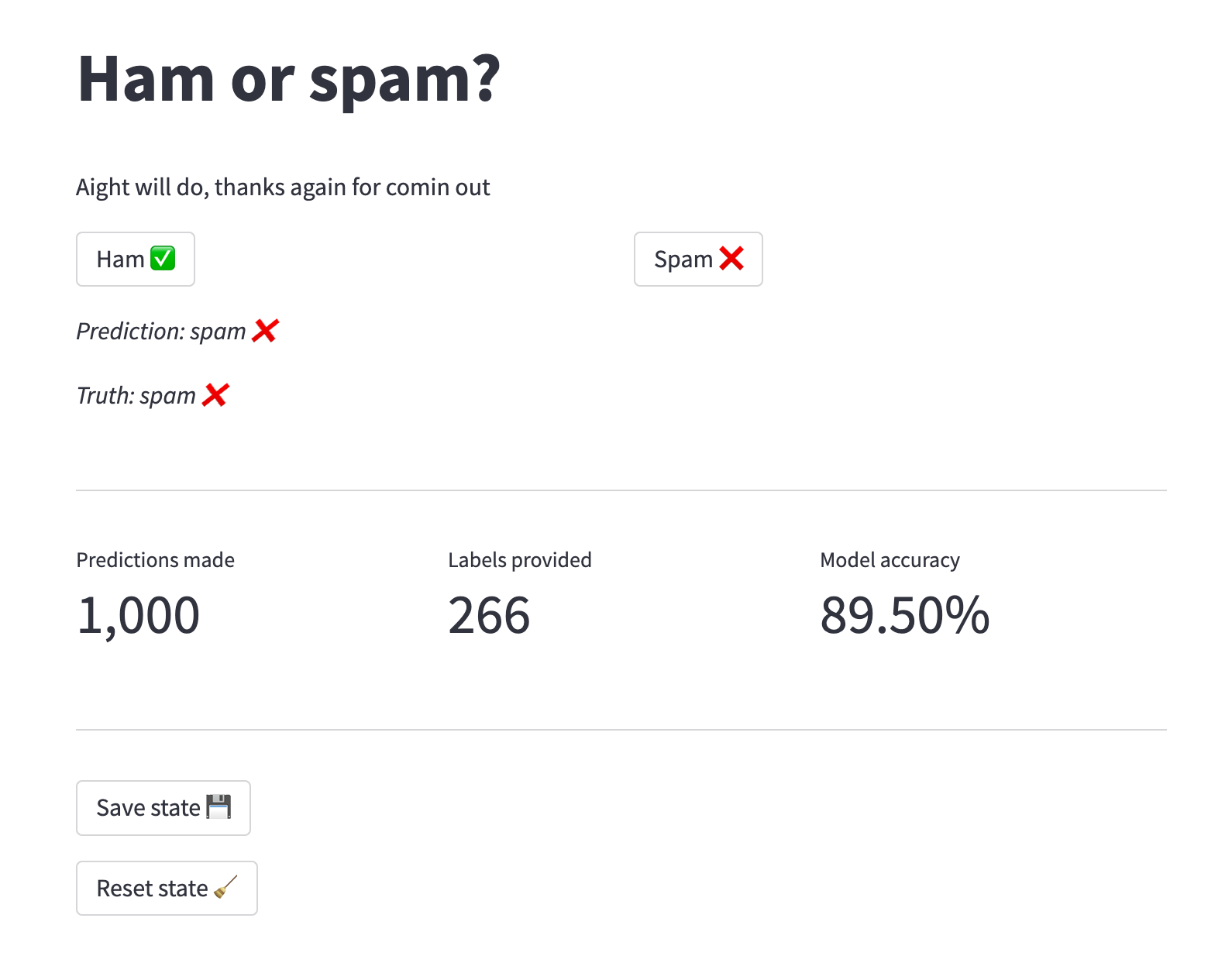
I’m actually using Databutton to host the demo. It’s basically a tool for building and deploying Streamlit apps. It also includes some convincing features, such as storage. This allows maintaining state in between sessions. If you like Streamlit, you’re going to love Databutton.
Here is the underlying code:
Click to see the code
import itertools
import pickle
import databutton as db
import streamlit as st
from river import active, datasets, feature_extraction, linear_model, metrics
st.title("Ham or spam?")
state = st.session_state
model = active.EntropySampler(
classifier=(
feature_extraction.BagOfWords()
| linear_model.LogisticRegression()
),
discount_factor=100,
seed=42,
)
if "model" not in state:
# Load state from storage
state["model"] = pickle.loads(
db.storage.binary.get("model.pkl", default=lambda: pickle.dumps(model))
)
state["metric"] = pickle.loads(
db.storage.binary.get(
"metric.pkl", default=lambda: pickle.dumps(metrics.Accuracy())
)
)
state["predictions"] = db.storage.json.get("predictions", default=lambda: {})
state["labels"] = db.storage.json.get("labels", default=lambda: {})
state["dataset"] = (
(str(i), x["body"], y)
for i, (x, y) in enumerate(datasets.SMSSpam())
if str(i) not in state["predictions"]
)
# Warm-start the first time
if not state["predictions"]:
for i, x, y in itertools.islice(state["dataset"], 1000):
y_pred, ask = state["model"].predict_one(x)
state["metric"].update(y, y_pred)
state["predictions"][i] = y_pred
if ask:
state["model"].learn_one(x, y)
state["labels"][i] = y
model = state["model"]
metric = state["metric"]
labels = state["labels"]
predictions = state["predictions"]
dataset = state["dataset"]
for i, x, y in dataset:
y_pred, ask = model.predict_one(x)
if ask:
break
else:
metric.update(y, y_pred)
predictions[i] = y_pred
st.markdown(x)
choices = st.columns(2)
with choices[0]:
if st.button("Ham ✅"):
model.learn_one(x, False)
labels[i] = False
predictions[i] = y_pred
metric.update(y, y_pred)
with choices[1]:
if st.button("Spam ❌"):
model.learn_one(x, True)
labels[i] = True
predictions[i] = y_pred
metric.update(y, y_pred)
st.markdown(f"*Prediction: {'spam ❌' if y_pred else 'ham ✅'}*")
st.markdown(f"*Truth: {'spam ❌' if y else 'ham ✅'}*")
st.markdown("""---""")
columns = st.columns(3)
columns[0].metric("Predictions made", f"{len(predictions):,d}")
columns[1].metric("Labels provided", f"{len(labels):,d}")
columns[2].metric("Model accuracy", f"{metric.get():.2%}")
st.markdown("""---""")
if st.button("Save state 💾"):
db.storage.binary.put("model.pkl", pickle.dumps(model))
db.storage.binary.put("metric.pkl", pickle.dumps(metric))
db.storage.json.put("predictions", predictions)
db.storage.json.put("labels", labels)
if st.button("Reset state 🧹"):
db.storage.binary.put("model.pkl", pickle.dumps(model.clone()))
db.storage.binary.put("metric.pkl", pickle.dumps(metric.clone()))
db.storage.json.put("predictions", {})
db.storage.json.put("labels", {})
The code should be straightforward to follow, but it might be confusing because some UI shenanigans are mixed with the core logic. I’ll break it down.
Managing state
state = st.session_state
I made heavy use of Streamlit’s Session State. Usually, taking an action in a Streamlit reruns the app from the app. Session State is a way to store state between successive reruns. Note that this is different from Streamlit’s cache annotation.
Defining an active learning strategy
model = active.EntropySampler(
classifier=(
feature_extraction.BagOfWords()
| linear_model.LogisticRegression()
),
discount_factor=100,
seed=42,
)
This is the first active learning strategy I recently added to River. It’s based on entropy: the idea is to ask for labels when the output probability distribution is somewhat uniform. It seems to be working reasonably well, but I’m sure we’ll implement better strategies over the coming months.
Loading state from storage
state["model"] = pickle.loads(
db.storage.binary.get("model.pkl", default=lambda: pickle.dumps(model))
)
state["metric"] = pickle.loads(
db.storage.binary.get(
"metric.pkl", default=lambda: pickle.dumps(metrics.Accuracy())
)
)
state["predictions"] = db.storage.json.get("predictions", default=lambda: {})
state["labels"] = db.storage.json.get("labels", default=lambda: {})
state["dataset"] = (
(str(i), x["body"], y)
for i, (x, y) in enumerate(datasets.SMSSpam())
if str(i) not in state["predictions"]
)
Databutton provides a storage API. Here I’m using this feature to load the current state of the app. The model and the metric are both Python class instances, and so I’m pickling them. The predictions and labels are simply stored in dictionaries, and are thus saved as JSON files.
I load the dataset from River. I skip the samples for which a prediction has already been made. This is what allows the app to not start from scratch each time it is rerun or reloaded.
Warming-up
for i, x, y in itertools.islice(state["dataset"], 1000):
y_pred, ask = state["model"].predict_one(x)
state["metric"].update(y, y_pred)
state["predictions"][i] = y_pred
if ask:
state["model"].learn_one(x, y)
state["labels"][i] = y
Active learning starts paying off once the model has seen a decent number of samples. At first, active learning usually always asks for samples to be labelled. This is a bit boring for a demo, so I warmed-up the model on the first 1000 samples.
Asking for a label
for i, x, y in dataset:
y_pred, ask = model.predict_one(x)
if ask:
break
else:
metric.update(y, y_pred)
predictions[i] = y_pred
Classifiers in River simply produce a prediction when predict_one or predict_proba_one is called. The way active learning works in River works, is that an additional ask boolean is returned, indicating whether a label is required or not. What I do is that I break the inference loop whenever a label is required.
Note: what happens after the else is a bit cryptic. Basically, in case ask is True, I’ll update the metric and store the prediction once the sample has been labelled. This is just a UX detail.
Displaying the sample
st.markdown(x)
Here we’re classifying spams in text messages, so we just need to display the content of the text in order for a human to label it.
Labelling the sample
choices = st.columns(2)
with choices[0]:
if st.button("Ham ✅"):
model.learn_one(x, False)
labels[i] = False
predictions[i] = y_pred
metric.update(y, y_pred)
with choices[1]:
if st.button("Spam ❌"):
model.learn_one(x, True)
labels[i] = True
predictions[i] = y_pred
metric.update(y, y_pred)
We’re doing binary classification, so I simply displayed two buttons. Clicking on a button will update the model with the according label.
As I mentioned above, I handle the prediction here because I don’t want the prediction to be accounted for if no label is picked and the page is reloaded. Again, this is just a UX thing to do with managing the state of the application.
Performance report
columns = st.columns(3)
columns[0].metric("Predictions made", f"{len(predictions):,d}")
columns[1].metric("Labels provided", f"{len(labels):,d}")
columns[2].metric("Model accuracy", f"{metric.get():.2%}")
I’m counting the number of predictions made by the model, along with the number of labels it has been fed. The larger the difference between these two quantities, the better the active learning strategy. Usually, this is also quite correlated with how well the model is performing.
Saving and resetting state
if st.button("Save state 💾"):
db.storage.binary.put("model.pkl", pickle.dumps(model))
db.storage.binary.put("metric.pkl", pickle.dumps(metric))
db.storage.json.put("predictions", predictions)
db.storage.json.put("labels", labels)
if st.button("Reset state 🧹"):
db.storage.binary.put("model.pkl", pickle.dumps(model.clone()))
db.storage.binary.put("metric.pkl", pickle.dumps(metric.clone()))
db.storage.json.put("predictions", {})
db.storage.json.put("labels", {})
What I like about this app is that the state is preserved if I reload the page. This is all thanks to Databutton. Having storage available on top of Streamlit is a sweet combo.
That’s all for now! If you’re interested in online active learning, please do reach out. We’ve barely started adding it to River, and would love to include state-of-the-art methods.