The online machine learning predict/fit switcheroo
Table of contents
Why I’m writing this
Fact: designing open source software is hard. It’s difficult to make design decisions which don’t make any compromises. I like to fall back on Dieter Rams’ 10 principles for good design. I feel like they apply rather well to software design. Especially when said software is open source, due to the many users and the plethora of use cases.
I had to make a significant design decision for River. It boils down to the fact that making a prediction with a model pipeline is a stateful operation, whereas users understandably expect it to be pure with no side-effects. This regularly comes up on the issue tracker, as you can see here, here, and here.
I usually tell people that it’s a feature, not a bug. It was a conscious design decision which I made to make users fall in the pit of success. What may seem like a detail actually sheds light on how online learning is fundamentally different from batch learning. I wrote down some stuff in a previous post, but I felt like a dedicated post on the topic was long overdue.
This blog post is a way for me to revisit the decision I made. Hopefully, by the end of this post, I’ll have convinced the reader and yours truly how online machine learning should be done. It may result in a couple of changes to the way River works.
The good old fit/predict paradigm
The one thing I most admire about scikit-learn is its profound influence on the way we think about machine learning tasks. Virtually every supervised learning task involves training a model – fit – and applying it to unlabelled data – predict. I don’t know how obvious this was before scikit-learn, but the popularity of the latter did a lot to set this paradigm in stone – and in our minds!
The fit/predict paradigm is ubiquitous because it’s intuitive. Fitting a model is a stateful operation that updates each component of said model. Predicting is a pure operation which simply runs an input through each component and produces an output. Kaggle and other competition platforms have sacralised this paradigm and made it pervasive.
What I find interesting is that the exact opposite happens in a production system. When a new sample arrives, the system first produces a prediction. The system learns from the sample once the associated ground truth reveals itself. That’s the whole point of using supervised learning in the first place: we want to predict an unknown quantity right now. We only get access to the truth afterwards.
It’s worth thinking beyond the offline setup where this fit/predict routine is usually done. In a production system, there’s new data regularly coming in. Predictions are initially made for these data points. The data can then be labelled. This generates new training data which can be used to retrain the system.
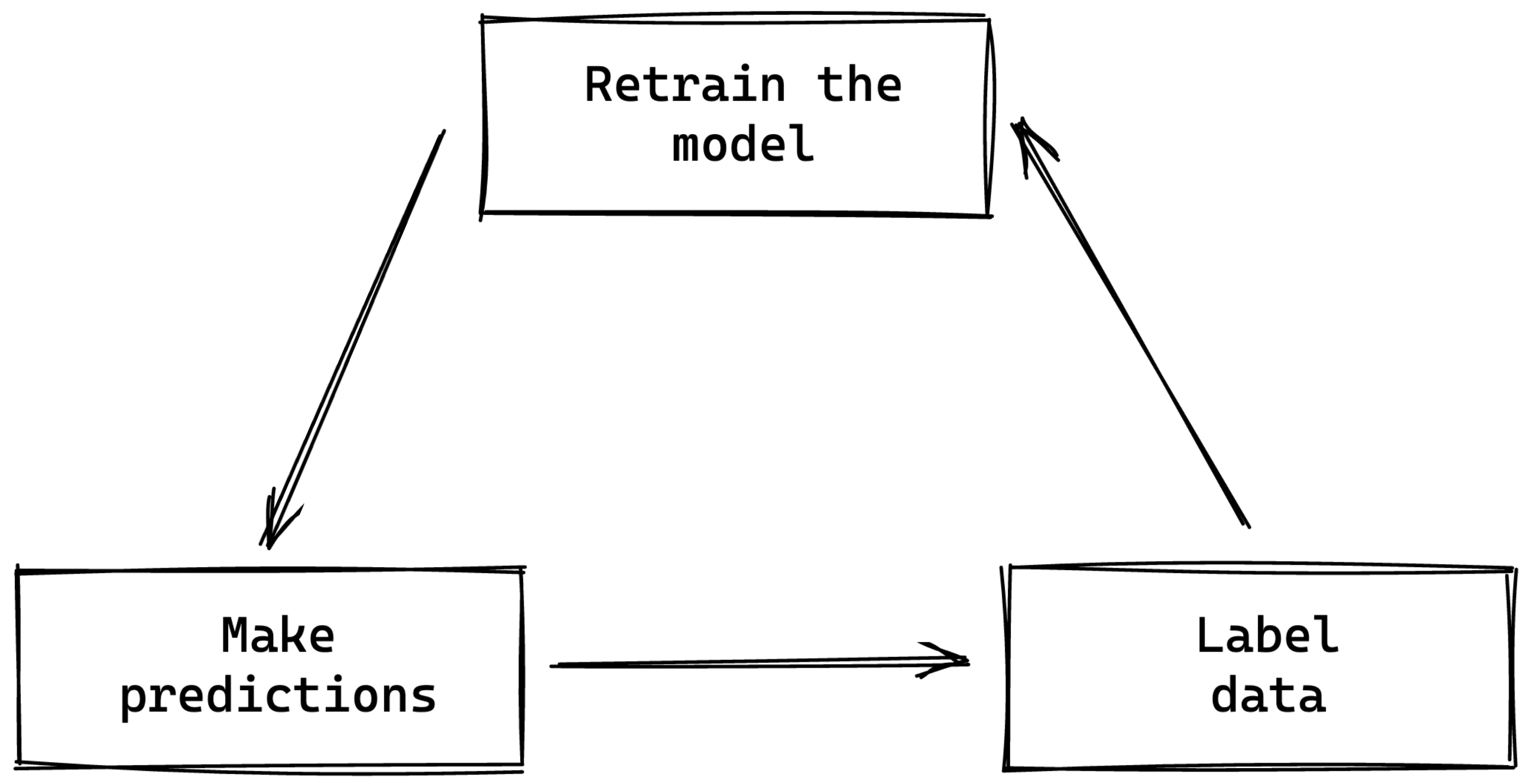
As of now, this is a very challenging process to put in place. Thankfully, the data science ecosystem is maturing in this direction. However, most solutions cater to batch systems that have to be retrained when data is available. I’m more interested in online systems which don’t need retraining. Their lifecycle is different.
It’s time for a switcheroo
An online machine learning model can learn incrementally. It doesn’t need access to the previous training data in order to learn from new training data. Online learning incurs a tradeoff. On the one hand, the model can be updated nearly instantaneously from newly labelled data. On the other hand, it is bound to be less performant than a batch model that has been trained on the same amount of data. An online machine learning approach makes sense when you want to learn as soon as new training data is available, instead of periodically retraining a batch model from scratch.
In an online setting, you don’t really split data into training and testing data. Every observation gets seen twice by the model. The first time is when a prediction is made when the features x arrive. The second time is when the model is updated with the pair (x, y) once the truth y is revealed at a later point in time. The beauty of this interleaving is that each prediction can be compared to the truth to obtain an out-of-fold performance estimate. This is called progressive validation. In other words, the stream of data acts as both a training set and a test set.
At first, this seems quite straightforward to put in place, as we’re simply reversing the fit/predict process, albeit in an online manner. And yet, as always, the devil is in the detail. The trick is that a model may be composed of unsupervised components as well as supervised ones. For instance, take the following River model, which is a pipeline that extracts some features, scales them, and then feeds them into a logistic regression.
from river.compose import Pipeline, Select, TransformerUnion
from river.feature_extraction import Agg, TargetAgg
from river.linear_model import LogisticRegression
from river.preprocessing import StandardScaler
from river.stats import Mean
model = Pipeline(
TransformerUnion(
# Unsupervised
Select('a', 'b', 'c'),
# Unsupervised
Agg(on='foo', by='bar', how=Mean()),
# Supervised
TargetAgg(by='bar', how=Mean())
),
# Unsupervised
StandardScaler(),
# Supervised
LogisticRegression()
)
When a new set of features x arrives, nothing is stopping us from updating the unsupervised components. In fact, it would be wasteful not to. Why wait until y is available? Why not just update these components during the prediction phase? We can always update the supervised parts later on once y is available.
This is definitely not a conventional idea. It stems from the fact that online learning makes it apparent that predictions are made before the model is updated. I didn’t get this idea from some textbook. It came to me after having spent a lot of time studying online learning. But I’m very fond of this idea. It also results in better performance, so I’m rather convinced that it’s correct.
This idea boils down to learning from unlabelled data during the prediction phase. We actually do something similar, albeit unknowingly, when we train batch models. This is quite apparent in a Kaggle competition. During the latter, it’s common practice to concatenate the training data with the test data before extracting features and preprocessing the data as a whole. This doesn’t necessarily lead to target leakage, as we’re simply learning the distribution of the data, either by calculating aggregate features or by scaling it with more accurate statistics.
Anyway, this is why River pipelines are stateful, and explains why some users are confused. If you take any River estimator individually, its learn_one method is stateful, and its predict_one – or transform_one – method is pure. However, in a pipeline, the predict_one method is stateful for the unsupervised components. Meanwhile, the learn_one method of a pipeline is only stateful for the supervised components. This means that when you predict with and train an online model pipeline, each component is updated as soon as the necessary information is available. You, the user, don’t have to worry about anything. You’ve fallen into the pit of success.
Stateful online learning
This post is a good occasion to talk about what I like to call “state” in online learning. In River, many of the examples in the documentation are simple loops over datasets. For instance, here’s the current example in River’s README:
from river import *
dataset = datasets.Phishing()
model = compose.Pipeline(
preprocessing.StandardScaler(),
linear_model.LogisticRegression()
)
metric = metrics.Accuracy()
for x, y in dataset:
y_pred = model.predict_one(x)
metric = metric.update(y, y_pred)
model = model.learn_one(x, y)
print(metric)
Accuracy: 89.20%
The prediction and training steps are perfectly interleaved with each other. Each one happens right after the other. However, if the goal of this online script is to simulate a production scenario, then this perfect interleaving might be too much of a simplification. In reality, there might be a delay between the moment when a prediction is made and when the truth is revealed. This delay may vary from one observation to the other. For instance, if you’re predicting the duration of taxi trips, then the delay varies: it’s the amount of time the taxi trip actually took.
If you’re running an online model in production, then you’ll want to store the features that were used for making a prediction. You can then grab these features when the truth is revealed and pair them together. This is informally referred to as a log and wait strategy. It’s quite different than generating the features from scratch once the truth is revealed. You really want to be using the features that were available when the prediction was made, not afterwards. This way you avoid data leakage. You also save yourself some computation/networking. I recommend reading this blog post from Faire for further detail.
What I call state is the information that was available when the model was asked to make a prediction. Having state implies you need some sort of database to store it while you wait for the ground truth to arrive. In some use cases where the delay is very short, such as CTR prediction, then you might get away by storing the state in memory because you don’t have to wait for long. But in many cases you’ll want some proper storage. What’s more, storing this information gives you the ability to re-run the model a posteriori.
Indeed, if you store the data correctly – the features, the true label, and their respective arrival times – then you can perform delayed progressive validation. Which is very cool, because then you’ll be doing an offline evaluation of your model as if it were in a production setting. The dream!
What about unsupervised models?
Some models don’t need labels to learn. For instance, take anomaly detection. Like any other estimator, an anomaly detector learns and makes predictions. So how is it different to any other unsupervised estimator, such as PCA or standard scaling? The answer depends on whether the model should learn from the features before making a prediction.
Generally speaking, it makes sense to first make a prediction, and then update the model. This is very much true for anomaly detection. An anomaly detector does not need a label to learn, and is therefore unsupervised. However, you first may want to predict an anomaly score for a sample before learning from it. Indeed, if you deem that the sample is an anomaly because the anomaly score is high, then you might not want to corrupt the model by learning from the sample.
But how about clustering? It might make sense to make a clustering model learn from the sample before labelling said sample. Maybe clustering models are a special case.
In River, at the moment, everything that is unsupervised is updated during the prediction/scoring phase. For instance, the learn_one method call in the following example doesn’t actually do anything:
from river import *
model = compose.Pipeline(
preprocessing.MinMaxScaler(),
anomaly.HalfSpaceTrees()
)
auc = metrics.ROCAUC()
for x, y in datasets.CreditCard():
score = model.score_one(x)
model = model.learn_one(x, y) # unnecessary
auc = auc.update(y, score)
This example is part of River’s current documentation, so it’s a bit of a mishap. If I’m totally honest, I hadn’t realised this edge-case until very recently!
I tend to think that the model updating should happen in the learn_one phase. Having everything happen in score_one is not intuitive, albeit it is still correct. This comes at the cost that an input has to go through the first n - 1 steps of the pipeline twice – once during score_one and once during learn_one.
A note on reinforcement learning
Disclaimer: I haven’t spent much time studying reinforcement learning. But I understand the underlying principles, and I also have a couple of friends doing their PhDs on the subject.
Reinforcement learning is a field where this predict/fit scenario applies very much. You could argue that reinforcement learning is a case of online learning. At the very least, there are connections between both fields. For instance, it seems to me that experience replay in reinforcement learning could and should be more popular in online learning.