Sh*t flows downhill, but not at Carbonfact
I’m writing this after watching the talk Joe Reis gave at Big Data LDN. It’s called Data Modeling is Dead! Long Live Data Modeling! It’s an easy-to-watch short talk that calls out on a few modern issues in the data world.
I’d like to bounce off one of Joe’s slides:

I’m aligned with Joe that many issues stem from the lack of unison between engineering and data teams. A fundamental aspect of the Modern Data Stack is to replicate/copy production data into an analytics warehouse. For instance, copying the production PostgreSQL database into BigQuery.
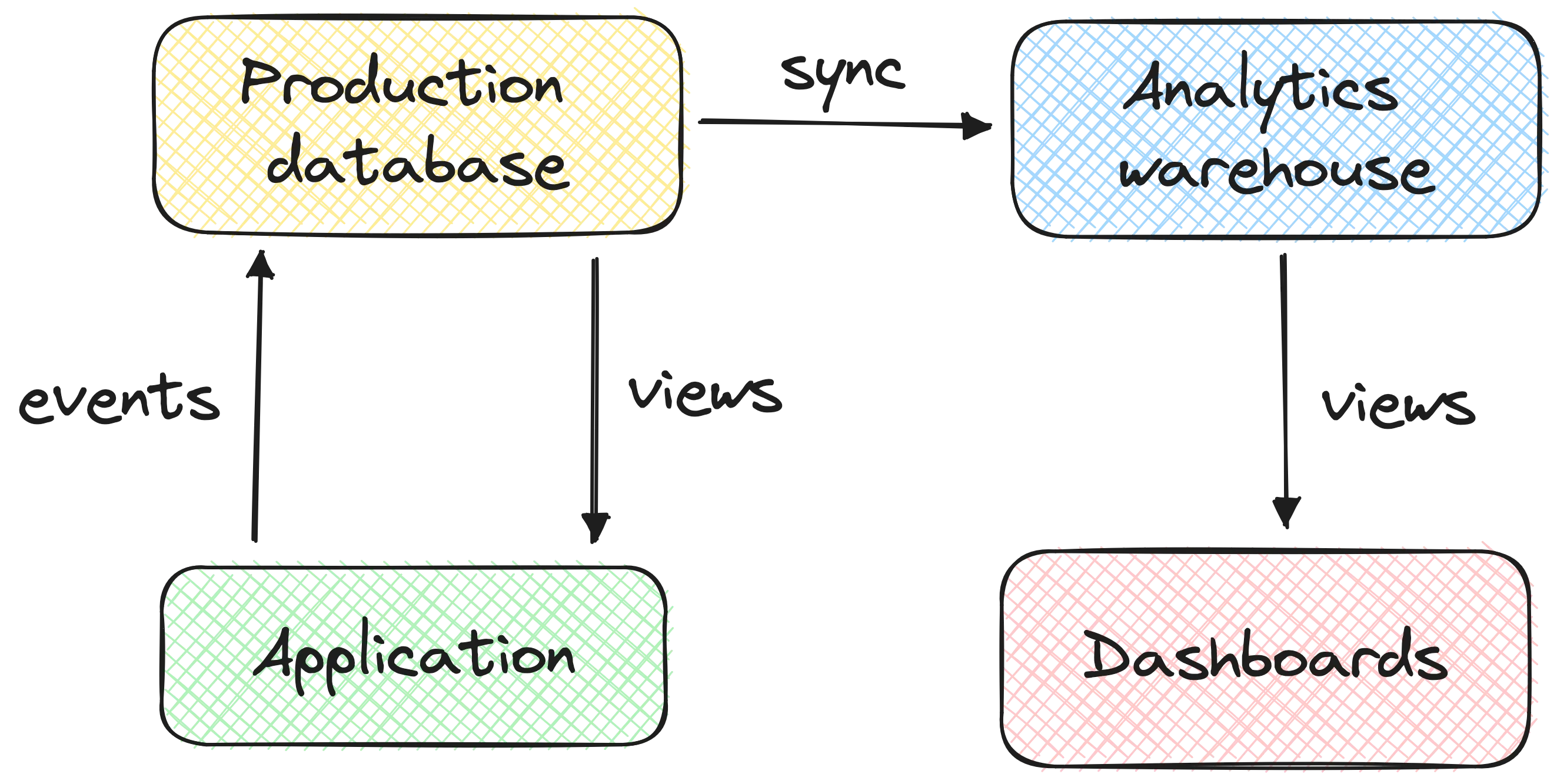
An undesired consequence of this setup is that the data team is at the mercy of the engineering team. For instance:
- Engineer Tom renames a field and doesn’t warn Data Engineer Alice
- During the daily dbt refresh, Alice is alerted on Slack
- Alice investigates 20 minutes, and spots the missing field
- Alice does a
git blameand identifies Tom as the culprit - Alice and Tom about this change
- Alice agrees to fix the dbt logic on the data side
- Alice renames to the previous name so downstream dashboards don’t break
- The same field is now named differently in two different places
I think this is a very inefficient situation. Alice, an expensive data engineer, shouldn’t have to waste time on low-value – and possibly boring – tasks. Tom shouldn’t have to worry about breaking things for the data team when he’s developing on the production application.
This was the reality when I worked at Alan. Our solution was to write a GitHub Action that would scan SQLAlchemy migration files in the production application pull requests, fetch the list of columns in use in the analytics views, compare the two, and in case of a conflict nudge the engineer to warn the data team before merging their pull request. This worked reasonably well, but it felt like duct tape on a problem that shouldn’t exist in the first place.
We do things differently at Carbonfact. Both the engineering and data teams consume the analytics warehouse – which is BigQuery. Carbonfact’s main piece of software is a platform our customers access. All the stuff customers see comes from the analytics warehouse, not the production database. That’s right: our analytics warehouse is customer-facing. Both our clients and our internal teams look at the same data. Having everyone’s eyes on a single source of truth makes it easier to spot issues.
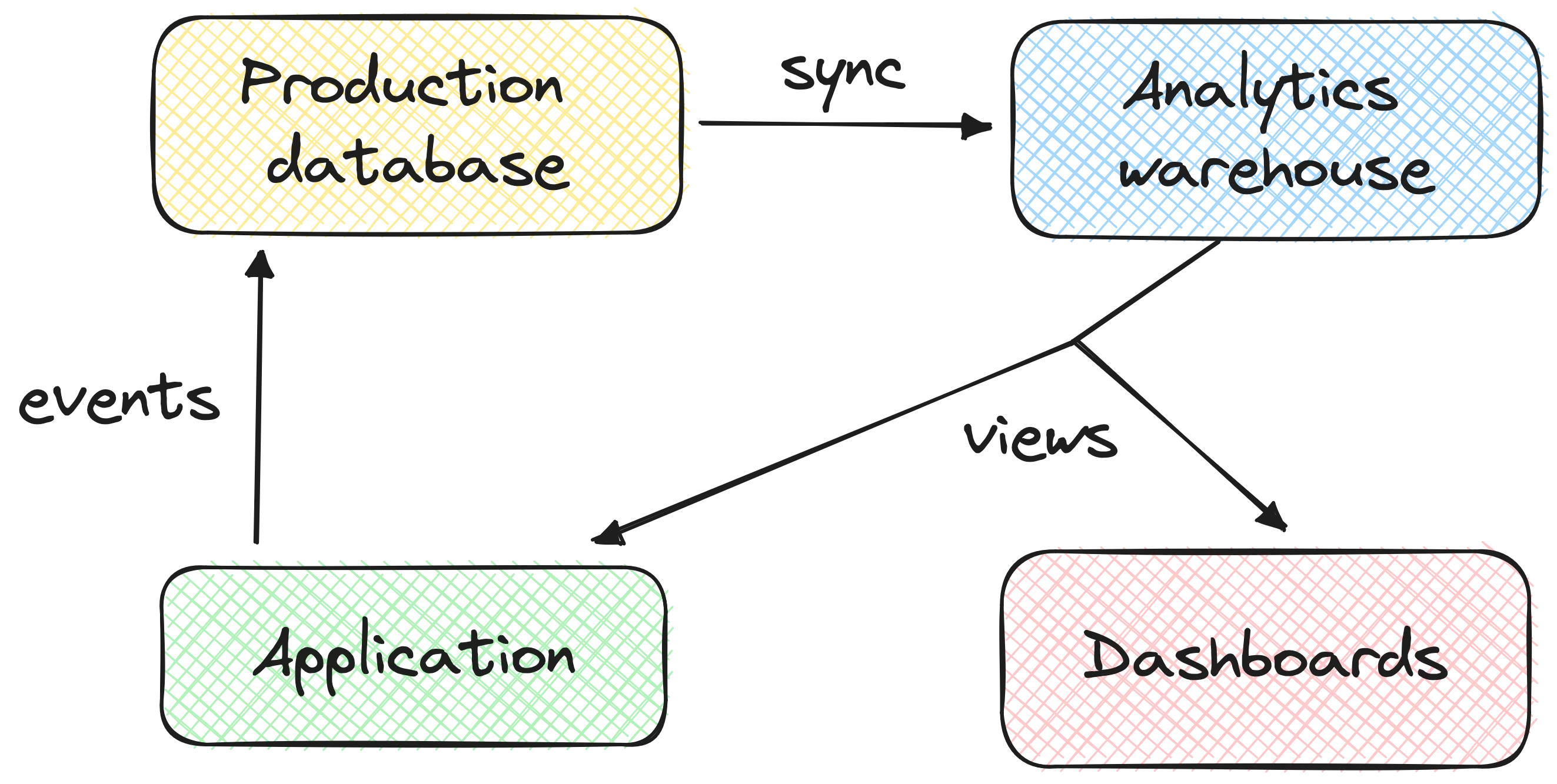
This vastly simplifies the way we work:
- The engineering and data team work together on maintaining the analytics views. I thus have a good relationship with the engineers, as we don’t work in silos.
- We have a dedicated
platformschema in our warehouse to hold views that are customer-facing. During continuous integration, we can detect in a pull request whether a customer-facing view will break or not. - Each business question only has one answer, which is provided by the analytics warehouse.
- The only times I’ve heard about inconsistent figures is because two views were doing the same thing, and one of them was wrong. This can be resolved by moving the logic into a shared view. The business logic is kept in one place.
- Sometimes engineers want to grab data from the analytics warehouse – think reverse-ETL – which is usually an anti-pattern. In our case it’s a non-issue because the application is already consuming the analytics warehouse.
What I most enjoy is that the analytics warehouse, as well as the data team, are at the core of the company. Stakeholders don’t have any other option than to trust the analytics warehouse, because there is no other source of information. This is a very different situation from the one I experienced at Alan, where the data team was a support function offering an analytics warehouse which wasn’t always used.
There is one downside to our approach: views need to be refreshed for data to be live on the customer platform. Our refresh takes ~150 seconds. We can afford this because we have slow moving data that doesn’t need to be shown in real-time – mainly reports. If we had real-time data, we would have to use a different approach, or switch to a streaming data warehouse.
I’d like to use this post to highlight an internal tool we’ve opensourced here at Carbonfact. It’s called lea. In a nutshell, it’s an alternative to dbt. Due to us pushing to place data at the core of Carbonfact, we felt there was an opportunity to build a tool tailored to our needs. We can experiment with it because we know it inside out. It is not as fully-fledged as dbt, but it does the job for us, including the engineering team. We’re happy to share it with the world!
Finally I want to mention I would have missed Joe Reis’ talk if it weren’t for blef.fr, which is an English newsletter written by a Frenchie that I highly recommend.